
Cite as: Davis, Daniel. 2013. “Modelled on Software Engineering: Flexible Parametric Models in the Practice of Architecture.” PhD dissertation, RMIT University.
3.0 – The Design of Software Engineering
To a computer, a parametric model reads as a set of instructions. The computer takes the inputs, applies the sequence of explicit functions, and thereby generates the parametric model’s outputs. “Anybody involved in any job that ultimately creates instructions that are executed by a computer, machine or even biological entity, can be said to be programming” argues David Rutten (2012), the developer of the popular parametric modelling interface, Grasshopper. This is not to say programming and parametric modelling are synonymous. There are clearly significant differences between designing architecture and designing software. Yet in both cases, there is a common concern with automating computation through sequences of instructions. Despite this “common ground” (Woodbury 2010, 66), and despite architects recognising that parametric modelling is often “more similar to programming than to conventional design” (Weisberg 2008, 16.12), the implications of the parallels between parametric modelling and software engineering remain largely unexplored. In particular, two pertinent questions remain unaddressed: if parametric modelling and software engineering both concern the automation of computers, do they both encounter the same challenges when doing so? And if they share the same challenges, are parts of their respective bodies of knowledge transferable in alleviating these challenges?
Woodbury, Aish, and Kilian (2007) have already shown that one area of software engineering – design patterns – is applicable to the practice of parametric modelling. Yet subsequently Woodbury (2010, 9) has been cautious in suggesting that architects can learn from software engineers, saying the practices “differ in more than expertise.” Woodbury (2010, 9) goes on to describe architects as “amateur programmers” who naturally “leave abstraction, generality and reuse mostly for ‘real programmers’.” In this chapter I will show how abstraction, generality, and reuse have not always been the foremost concern of ‘real programmers’, and how Woodbury’s assessment of contemporary architects could equally apply to past software engineers. Thus, while Woodbury (2010, 9) sees today’s architects as amateur programmers who are largely disinterested in software engineering, past preferences need not inform future practices. Given the success Woodbury et al. (2007) have had at improving the practice of parametric modelling with knowledge from software engineering, there is reason to suspect many more parts of the software engineering body of knowledge are also applicable to the practice of parametric modelling.
In this chapter I aim to identify the areas of knowledge employed by software engineers that could potentially help architects creating flexible parametric models. I begin the chapter by discussing how programmers once faced a software crisis not too dissimilar to the challenges architects are currently facing with their parametric models. I go on to discuss the body of knowledge that helped programmers overcome the software crisis and hypothesise about which aspects of this body of knowledge may be applicable to the practice of parametric modelling.
3.1 – The Software Crisis
In the 1960s, around the time that Ivan Sutherland was creating Sketchpad, a number of big software projects unexpectedly failed. These failures “brought big companies [like IBM] to the brink of collapse” recalls Turing award-winner Niklaus Wirth (2008, 33) in his Brief History of Software Engineering.1 The most shocking feature of the failures is that they happened during a period of substantial progress in computation; a period where newly invented third-generation programming languages were running atop processors with exponentially increasing speeds (Wirth 2008, 33). Yet, despite these advances, projects were coming in significantly over budget, they were late or, even worse, they were abandoned. A notable example is IBM’s System/360 project, managed by Frederick Brooks, which in 1964 was one of the largest software projects ever undertaken. The size of the project was possible since computers had become “several orders of magnitude more powerful” (Dijkstra 1972, 861) but the size of the project also amplified fundamental problems with programming. These problems could not be overcome by hiring several orders of magnitude more programmers. “Adding manpower to a late software project makes it later” says Brooks (1975, 25) reflecting on his management of System/360 in the seminal software engineering book, The Mythical Man-month. In the end, IBM’s ambitious System/360 unification, like many software engineering projects in the 1960s, was years late and cost millions of dollars more than budgeted (Philipson 2005, 19).
And so began the software crisis, a period when the hope borne of the relentless progression of computation was crushed; not by processing speeds derailing from their unlikely exponential increases but rather “crushed by the complexities of our own making” (Dijkstra 1997, 63); crushed by the challenge of simply writing software (Dorfman and Thayer 1996, 1-3). Wirth (2008, 33) observes “it was slowly recognized that programming was a difficult task, and that mastering complex problems was non-trivial, even when – or because – computers were so powerful.” This realisation resembles the current situation in architecture, where the vast improvements in parametric modelling over the past decade have exposed the difficulties of simply creating a parametric model. In much the same way architects may blame themselves for failing to anticipate changes to an inflexible parametric model, programmers feared human cognition, not computer power, would be the limiting factor in the application of computation. This idea was so alarming that in 1968 NATO assembled a team of scientists “to shed further light on the many current problems in software engineering” (Naur and Randell 1968, 14).
The NATO Software Engineering conference was a watershed moment. Amongst discussions of whether anyone had died from the software crisis2 was talk of “slipped schedules, extensive rewriting, much lost effort, large numbers of bugs, and an inflexible and unwieldy product” (Naur and Randell 1968, 122). These issues describe, almost word-for-word, the challenges many architects face when using parametric models (see chap. 2.3). In responding to these difficulties, the inclination at the NATO conference was to gather data rather than rely on intuition. The term Software Engineering originates from the conference’s title, which is a provocative attempt to “imply the need for software manufacture to be based on the types of theoretical foundations and practical disciplines, that are traditional in the established branches of engineering” (Naur and Randell 1968, 13). In this respect, the discipline of software engineering arises as a direct response to the software crisis; an attempt to overcome the crisis through a reasoned understanding of software manufacturing.
Boehm’s Curve
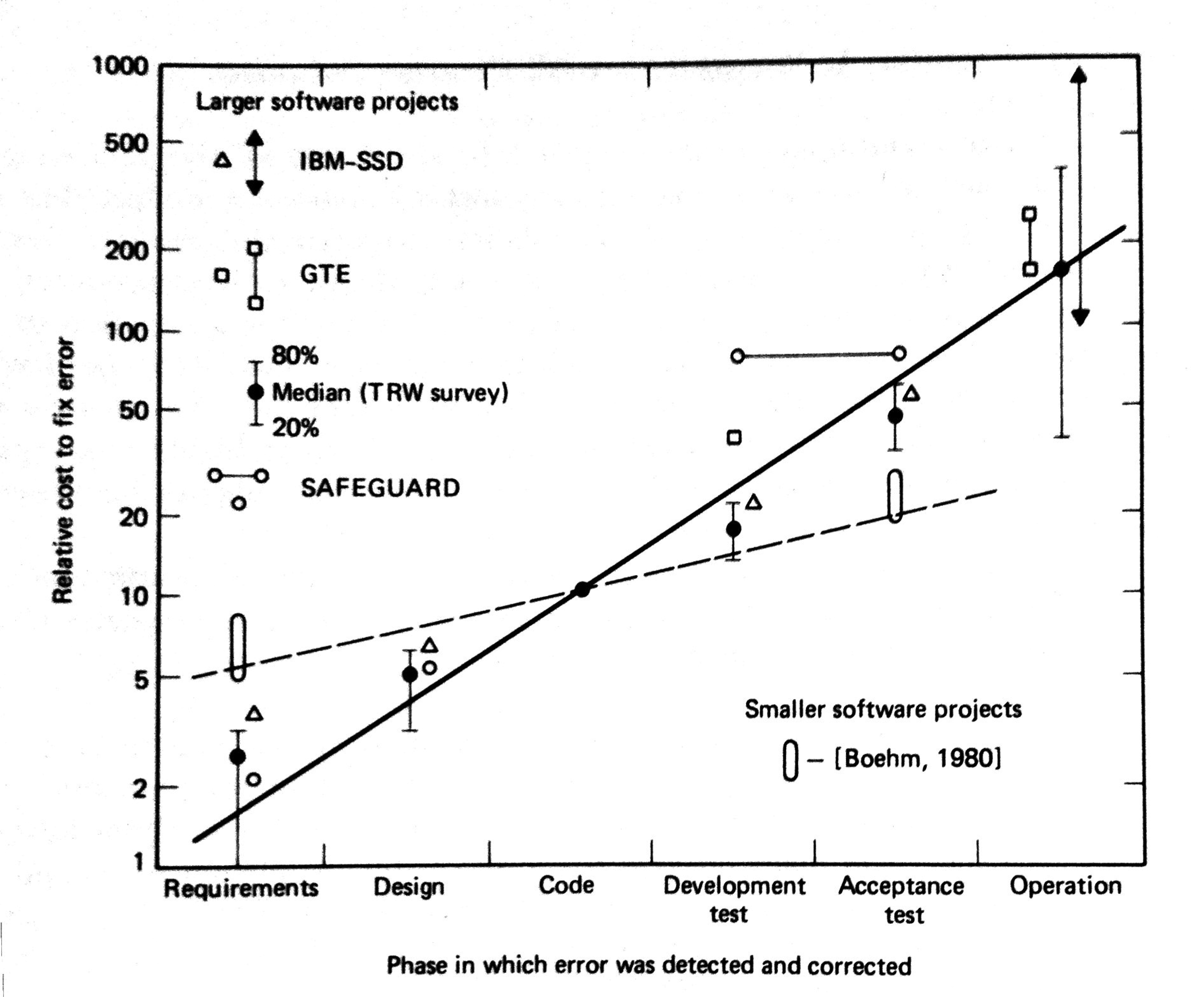
Figure 11: Boehm’s curve (1981, 40). An elaboration of Boehm’s earlier curve (1976, 1228). Note that Boehm plotted the data logarithmically. When plotted on a linear scale it resembles figure 12, which closely matches Paulson (fig. 9) and MacLeamy’s curve (fig. 10).
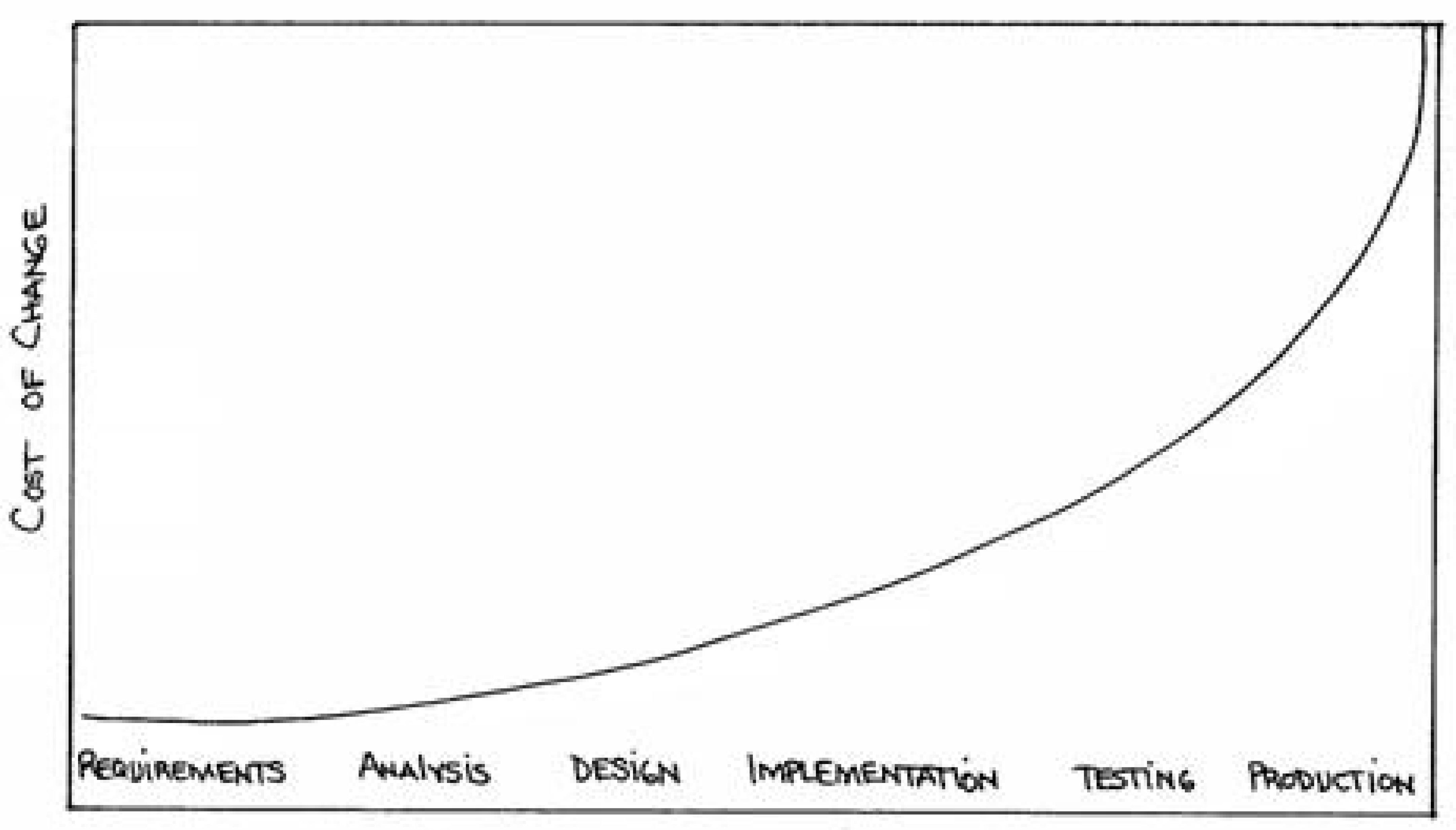
Figure 12: Boehm’s curve plotted on a linear scale (Beck 1999, 26).
Barry Boehm did not attend the 1968 NATO conference but it clearly influenced him. As the attendees of the conference had done, Boehm warned in 1972 that software “was often late and unreliable, and that the costs were rising” (Whitaker 1993, 300). This was considered a “shocking conclusion at the time” (Whitaker 1993, 300) and the United States Air Force, who had commissioned the study, refused to publish the findings, which they “rejected out of hand” (1993, 300). Boehm returned four years later with a paper bearing the same title as the NATO conference: Software Engineering (Boehm 1976). In this paper Boehm (1976, 1126-27) once again produced graphs showing that software was becoming more expensive than the hardware it ran on. However, the paper is perhaps better known for another graph it contains, a graph that has come to be known as Boehm’s curve (fig. 11; 1976, 1228; 1981, 40).
Boehm’s curve (fig. 11) observes that as a computer program becomes more developed, it also becomes more difficult to change. This was the same observation Paulson (1976, 588) had made about architecture projects that same year (see chap. 2.2).3 Paulson and Boehm’s curves have the same axes, the same shape, and the same conclusion. The major difference is that Boehm’s curve has supporting data while Paulson’s curve is more a diagram of what he thought was happening. The data in Boehm’s curve forecasts that making a change late in a software project costs one hundred times more than making the same change at the project’s inception. In effect, a software project – like an architecture project – becomes substantially less flexible over time and, as a result, the programmer’s capacity to make changes is greatly diminished by the increasing cost of change.
Beck’s Curve
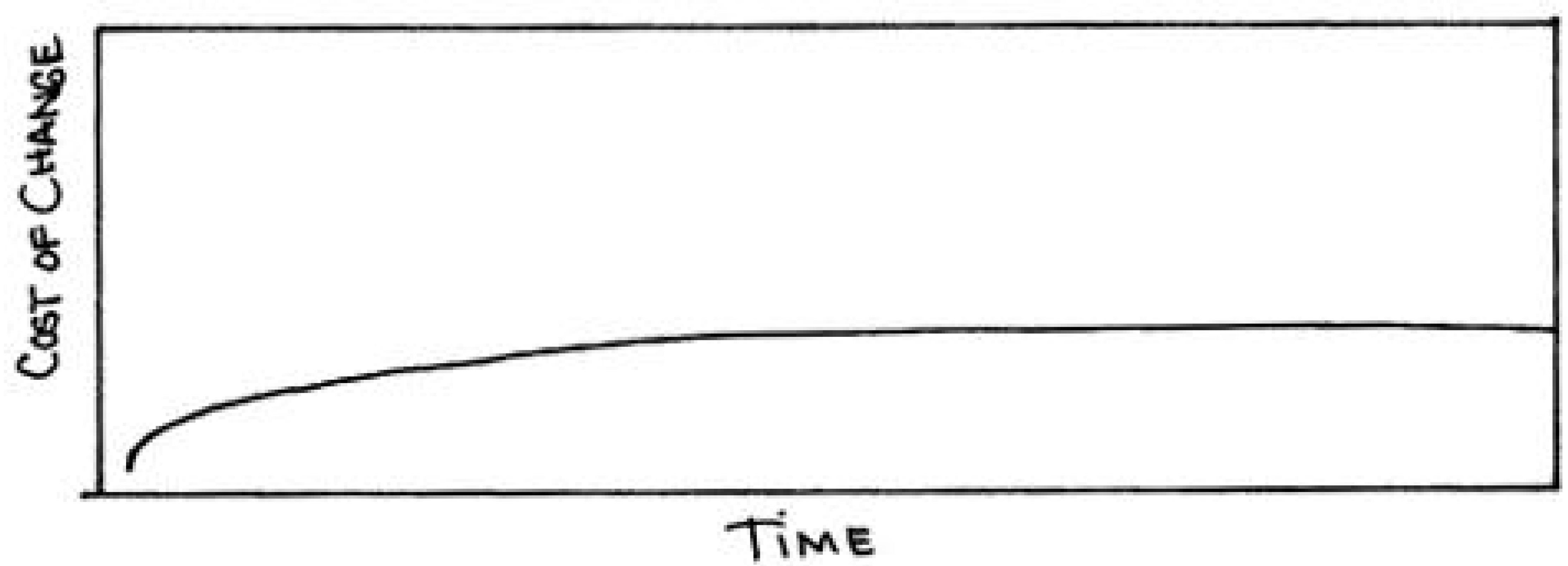
Figure 13: Beck’s curve (1999, 28). There are no project stage demarcations on the horizontal axis because the relatively constant cost of change allows the project to cycle rapidly through iterations, which enables traditionally early stage activities, like developing the project requirements, to continue late into the project – and vice versa (Beck 1999, 28).
Some programmers reacted to Boehm’s curve by trying to avoid change, their rationale being that if a change costs one hundred times more to make at the end of the project, then it makes sense to spend considerable time upfront preventing any late-stage changes. This is the same premise and conclusion that led MacLeamy to advocate the front-loading of architecture projects to avoid late-stage changes (see chap. 2.2). For software engineers, a common way to suppress change is with Winston Royce’s (1970) waterfall method. In the waterfall method, a project is broken down into a series of stages: requirements, design, implementation, verification, and maintenance. The breakdown resembles the stages routinely used in architecture and engineering projects. Each stage is completed before proceeding to the next, with the hope being that if the requirements are finalised before commencing the design (or any other subsequent stage), then there will be no late changes from unexpected alterations to the requirements (or any other proceeding stage). Of course, finalising the requirements without seeing the design is a tricky proposition (Microsoft 2005).
Royce (1970) was aware of the waterfall method’s shortcomings having originally introduced it as an example of how not to organise a software project. The waterfall method was, in fact, Royce’s antithesis. Royce (1970, 329) warned that the waterfall method was “risky and invites failure”, yet to his dismay, many of Royce’s readers disagreed with him and instead sided with the logic of what he was arguing against. The waterfall method became what Boehm (1988, 63) describes as “the basis for most software acquisition standards,” perhaps due to its clean hierarchical divisions of labour and affinity for fitting in a Gantt chart.
The method Royce (1970, 329-38) intended to advocate took the waterfall’s sequential progression and broke it with eddies of feedback between the stages. This idea was extended by Boehm (1981, 41) who argued the cost of making late-stage changes was so high that in some cases it might be more effective to make successive prototypes with feedback between each iteration. Boehm (1988) later formalised this method into the Spiral Model of software development, which, much like Schön’s Reflective Practice (1983), coils through stages of creating prototypes, evaluating the prototypes, reflecting upon the prototypes, and planning the next stage of work. This designerly way of approaching programming forms the basis of the Manifesto for Agile Software Development (Beck et al. 2001a). The manifesto’s fourth and final demand urges programmers to “respond to change over following a plan” (Beck et al. 2001a) – a demand that at once attacks the perceived rigidity of the waterfall method’s front-loading whilst also suggesting that Boehm’s cost of change curve need not be a barrier to making change. A number of programming methodologies fall under the banner of agile development, which includes Extreme Programming, Agile Unified Process, and Scrum. Kent Beck, the first signatory to the agile manifesto and the originator of Extreme Programming, captures the motivations of these methods in a book subtitled Embrace Change:
The software development community has spent enormous resources in recent decades trying to reduce the cost of change—better languages, better database technology, better programming practices, better environments and tools, new notations. What would we do if all that investment paid off? What if all that work on languages and databases and whatnot actually got somewhere? What if the cost of change didn’t rise exponentially over time [figure 12], but rose much more slowly, eventually reaching an asymptote? What if tomorrow’s software engineering professor draws [figure 13] on the board?
Beck 1999, 27
Beck provocatively suggests that Boehm’s curve (fig. 12) is no longer relevant when programmers have knowledge of “better languages, better database technology, better programming practices, better environments and tools, new notations” (Beck 1999, 27). In effect, Beck says that programmers can flatten the cost of change with the body of knowledge associated with software engineering. This flattening is now known as Beck’s curve (fig. 13). An important implication of Beck’s curve is that the demarcations between project stages (such as: requirements, design, and production) have less importance since a relatively constant cost of change allows “big decisions [to be made] as late in the process as possible, to defer the cost of making the decisions and to have the greatest possible chance that they would be right” (Beck 1999, 28). This was a bold prediction in 1999, but increasingly studies are indicating that software engineers have gained the knowledge to lower the cost of changes. A large industry survey by the Standish Group (2012, 25) concludes “the agile process is the universal remedy for software development project failure. Software applications developed through the agile process have three times the success rate of the traditional waterfall method and a much lower percentage of time and cost overruns.” This seems to carry through into the practice of software engineering, with Dave West and Tom Grant (2010, 2) showing that programmers now use agile development more often than the waterfall method. While these results do not speak directly to Beck’s curve, it is important to remember that “a flattened change cost curve makes [agile development] possible” (Beck 1999, 28). Remarkably, in only forty years, software engineering has gone from a point of crisis where the cost of late-stage changes seriously threatened the entire industry, to a point where the majority of software engineers are using a development method whose central tenet is to “welcome changing requirements, even late in development” (Beck et al. 2001b). As Beck (1999, 27) points out, the road out of the software crisis was “decades [of] trying to reduce the cost of change” now captured in an extensive body of knowledge related to software development.
3.2 – The Software Engineering Body of Knowledge
There is reason to suspect the body of knowledge concerning software engineering may also apply to architects using parametric models. Frederick Brooks (2010) makes a similar connection in his book The Design of Design, where he recounts designing his house and relates this to his experiences managing the design of IBM’s System/360 architecture (2010, 257-346). Brooks (2010, 21) says change is inevitable for both programmers and architects since they both normally begin with “a vague, incompletely specified goal, or primary objective” only clarified through iteratively creating and changing prototypes. These difficulties are compounded in the two practices, both by the fact that the cost of change generally rises exponentially as a project progresses, and by the fact that undetermined outcomes need to be expressed in logically precise instructions for the computer. While this problem is relatively new for architects creating parametric models, the same problem has challenged software engineering for decades. Evidence suggests that the knowledge software engineers have gained during this time allows them some control over the cost of change. This knowledge could potentially do the same in architecture.
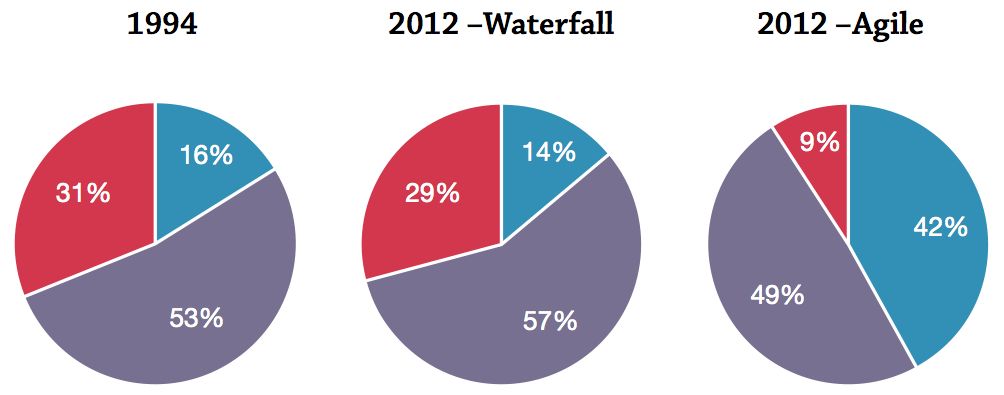
Figure 14: The success and failure rates of software projects according to The Standish Group’s industry survey (1994; 2012). Blue: Successful projects – delivered on-time, on-budget, and with the planned features. Purple: Challenged projects – either: over time, over budget, or lacking features. Red: Failed projects – the project was abandoned.
There are two main caveats in applying software engineering to parametric modelling. One caveat is that software engineers are often not particularly successful at what they do. On average, 49% of software projects using an agile development process will encounter significant challenges while 9% will fail outright. Just 42% of software projects are delivered on time, on budget, and with the specified features (fig. 14). While a 42% success rate may sound low, the Standish Group (2012, 25) says this represents the “universal remedy for software development project failure” principally because software engineers have historically had a success rate of only 16% (fig. 14; The Standish Group 1994). Thus, even software engineers following the best practices still encounter trouble more than they encounter success.
Another important caveat is that creating software is similar, but not identical, to creating architecture. Broadly speaking, some common points of difference include the following:
- The user: Software engineers tend to make software used by other people, whereas architects generally create parametric models for either themselves or for their colleagues.
- The product: Software engineers make software but architects ultimately make architecture rather than parametric models. While software may be evaluated in and of itself, a parametric model is typically valued for the architecture it produces.
- Team size: Software engineering teams range from lone individuals building an app, to thousands of developers creating an operating system. In comparison, parametric models are generally made by teams at the smaller end of this range.
- Project lifetime: Software engineering projects may last anywhere from a few minutes to a few decades, whereas the code in a parametric model is unlikely to persist beyond a few years (or perhaps even months).
There will be numerous exceptions to these broad generalisations. The point, however, is that while architects and software engineers share similar challenges, not all of software engineering is equally relevant to the idiosyncratic circumstances of parametric modelling. In this section I outline the software engineering body of knowledge and hypothesise about which parts are most pertinent to the practice of parametric modelling.
Classifying Knowledge
There have been a number of attempts to classify knowledge relating to software engineering. In 1997, the Institute of Electrical and Electronic Engineers (IEEE) formed a committee tasked with creating the first “comprehensive body of knowledge for software engineering” (Hilburn et al. 1999, 2). This was a controversial undertaking. The Association for Computer Machinery (ACM) feared the body of knowledge “would likely provide the basis for an exam for licensing software engineers as professional engineers” (ACM 2000). The ACM, like many others, withdrew their support of the project. The IEEE committee’s four-year schedule dragged into seven years of deliberation. Meanwhile, Thomas Hilburn et al. (1999) sidestepped the IEEE committee to produce their own, and the first, Software Engineering Body of Knowledge Version 1.0 (SWEBOK.1999; fig. 15). This document captured the expected knowledge of a programmer who has spent three years in the industry, and was released in conjunction with Donald Bagert et al. (1999) corresponding Guidelines for Software Engineering Education Version 1.0 (SE.1999). Eventually, in 2004, a similar pair of documents was published by the IEEE committee: Alain Abran and James Moore’s (2004) Guide to the Software Engineering Body of Knowledge (SWEBOK.2004) along with Jorge Díaz-Herrera and Thomas Hilburn’s (2004) Software Engineering 2004: Curriculum Guidelines for Undergraduate Degree Programs in Software Engineering (SE.2004).

Figure 15: Comparison of various Software Engineering Bodies of Knowledge (click for larger image). Blue: Equivalent knowledge areas. Red: Areas of knowledge applied to parametric modelling in my research.
The relationship between the various SWEBOK is shown in figure 15. While the taxonomies are different, they all use the waterfall method as a template for classifying the software engineering process. This is not an endorsement of the waterfall method since the division of knowledge need not prescribe its deployment. For example, projects using an agile methodology necessarily apply knowledge of planning and coding and testing, although not in the same linear fashion as projects using the waterfall method. With each SWEBOK agnostically employing the waterfall method’s stages, the key differences between the various SWEBOK lie in the classification of knowledge not pertaining to the waterfall’s stages. The SWEBOK.1999 clearly segregates these areas, with waterfall’s stages confined to the engineering category, which is separated from the computing fundamentals category and the software management category. While software management reappears in all the other SWEBOK, the computing fundamentals category is unique to the SWEBOK.1999 and covers areas of knowledge – like computer hardware and programming languages – that are potentially applicable to parametric modelling. For this reason, I have selected the SWEBOK.1999 to use in the following pages as I hypothesise about which parts are also applicable to architects creating parametric models. However, given the relative homogeneity of the various SWEBOK, I would expect similar results from using any of the other SWEBOK.
1. Computing Fundamentals
The Computing Fundamentals [1] category of the SWEBOK.1999 covers the foundational theories and concepts of software engineering. Many parts of this category are so essential to computing that they already necessarily contribute to parametric modelling. For instance, Computer Architecture [1.2] concerns the underlying structure of a computer, which includes the way transistors are laid out to allow more intensive calculations, and how networks exchange data to permit remote collaboration. Deriving the benefits of this knowledge requires no intervention from the software engineer or parametric modeller since it is encapsulated within a computer’s hardware. The same is true of both the Mathematical Foundation [1.3], which provides the formal logic to programming, and of Operating Systems [1.4], which provides the framework supporting the software. While the Computer Architecture [1.2], the Mathematical Foundations [1.3], and Operating Systems [1.4] have made large contributions to software engineering, these contributions come – in many ways – independent of the actions from software engineers. By proxy, designers are already benefiting from these areas of Computing Fundamentals [1] whenever they purchase new computer hardware or invest in new operating systems.
Algorithms and Data Structures [1.1] are not built into hardware and must instead be actively fashioned for a particular task. Considerable research has gone into tailoring Algorithms [1.1.2] and Data Structures [1.1.1] for parametric modelling. Examples of existing Algorithms [1.1.2] used in parametric modelling include algorithms for propagating changes through parametric models (Woodbury 2010, 15-16), rationalisation algorithms for simplifying complex surfaces (Wallner and Pottmann 2011), algorithms for simulating physical properties (such as: Piker 2011), and many proprietary algorithms buried in commercial software and geometry kernels (such as: Aish et al. 2012). Similar work has been done on Data Structures [1.1.1] to develop specialised file formats for things like sharing BIM models, describing B-rep geometry, and saving parametric models. While there is scope to further these existing Algorithms [1.1.2] and Data Structures [1.1.1], any improvements are likely to be refinements of what already exists. Given the maturity of the research in this area, I see few opportunities to address the flexibility of parametric models through making further contributions to Algorithms and Data Structures [1.1].
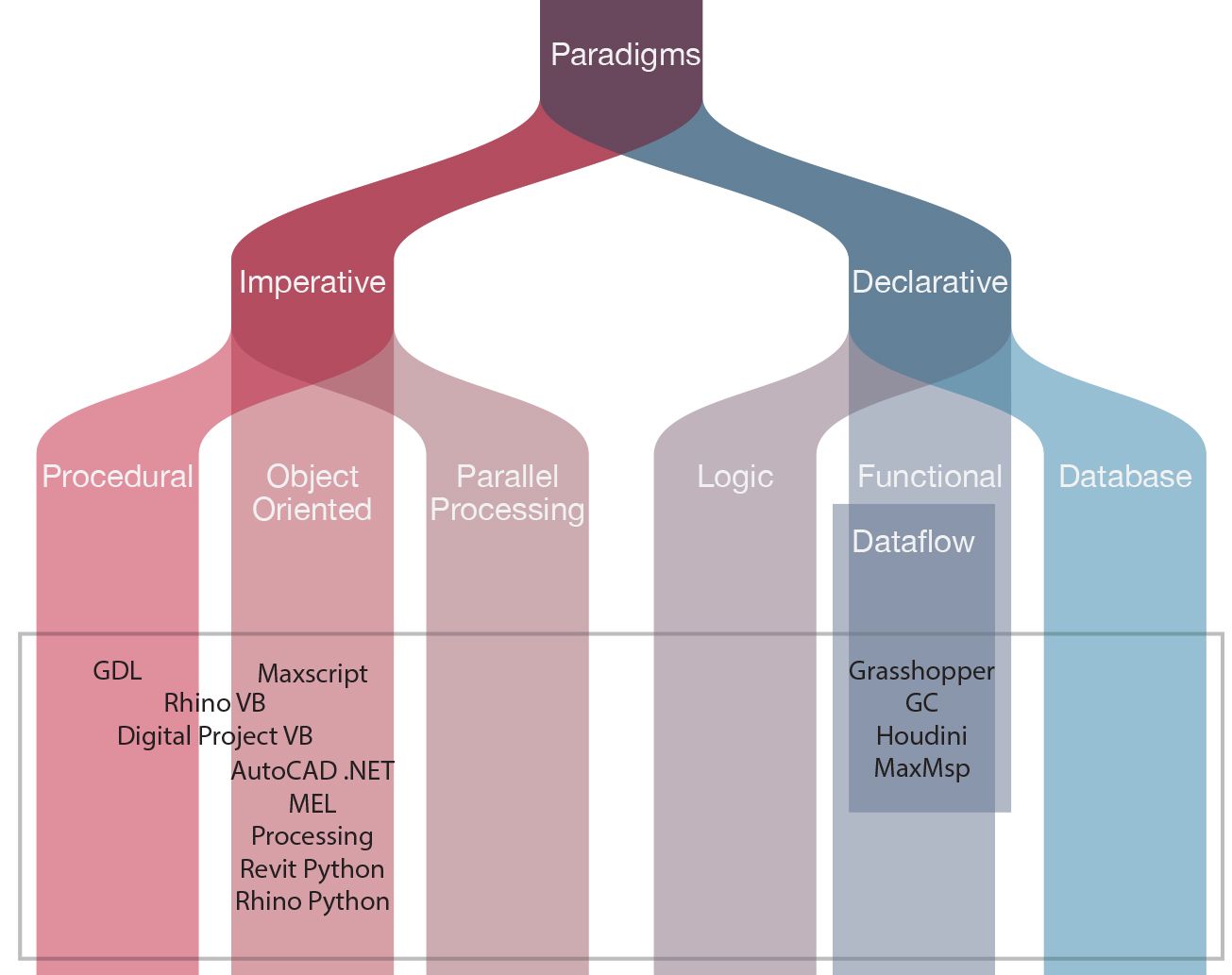
Figure 16: The programming languages architects use categorised by Appleby and VandeKopple’s (1997, xiv) taxonomy of programming paradigms.
As with Algorithms and Data Structures [1.1], there are already many Programming Languages [1.5] for architects creating parametric models. Every programming language has a unique style for expressing concepts, which is called the language’s Programming Paradigm [1.5.2] (fig. 16). The paradigm influences how problems are solved in a particular language. For instance, Appleby and VandeKopple (1997, 7) show how the United States Department of Defense addressed problems of “unmaintainable” and “fragile” software by creating a new multi-paradigm programming language, Ada (first released 1980). Appleby and VandeKopple (1997, xiv) divide programming paradigms – as many others do – into imperative paradigms and declarative paradigms (fig. 16). I will explain these denominations later in chapter 5 but for now it suffices to say that there is a broad taxonomy of possible programming paradigms. Currently architects only have access to two narrow bands of programming paradigms (see distribution in figure 16): the major textual CAD programming languages4 are all predominantly imperative with a bias towards procedural programming; whereas, the major visual CAD programming languages5 all reside in a very narrow subsection of declarative programming known as dataflow programming. While the two bands of paradigms occupied by CAD programming languages are well researched, they are ultimately limited. For architects this means they have a confined range of styles available to express ideas programmatically. This presents an opportunity to expand the practice of parametric modelling by borrowing new programming paradigms from software engineers.
2. Software Product Engineering
The Software Product Engineering [2] category of the SWEBOK.1999 describes the activities involved in producing software. These activities are categorised by the phases of the waterfall method. As I explained in the preceding pages, the divisions do not prescribe that software engineers use the waterfall method since these categories are intended to capture the knowledge necessary for producing software independent of the overall programming process.
Software Product Engineering’s [2] first area of knowledge is Software Requirements Engineering [2.1], which pertains to the creation of project briefs. By and large there is nothing particularly remarkable about the way programmers create briefs. Like in other disciplines, they analyse the situation [2.1.1], generate requirements [2.1.2], and write specifications [2.1.3]. While these are important steps in producing software, they are a process architects are likely already adept at.
From the Requirements [2.1] flows the Software Design [2.2], which in software engineering concerns the design of interfaces as well as the structure of code, data, and algorithms. Spending time structuring code rather than writing code has not always been a pastime of programmers. Prior to the software crisis, most programming languages (like FORTRAN) did not have a syntax for describing structure. The resulting programs generally had what Bertrand Meyer (1997, 678) calls, the “unmistakable ‘spaghetti bowl’ look” of logic weaving haphazardly through unstructured code. Edsger Dijkstra (1968, 148) called the unstructured jumps “harmful” and “too much an invitation to make a mess of one’s program” (an observation he made in the same year as the NATO Software Engineering conference). In the ensuing years, most programming languages have adopted Böhm and Jacopini’s (1966) concept of enforcing structure with conditionals, loops, and subprograms. Meyer (1997, 40-46) argues that these structures help to decompose incomprehensibly large problems into vastly more understandable smaller structured chunks.6 Despite these benefits, most parametric software has only rudimentary support for structure, which the vast majority of architects – like programmers prior to the software crisis – shun in favour of unstructured models (the low rates of structure are revealed and discussed in chapter 6.3). Woodbury, Aish, and Kilian’s (2007) Some Patterns for Parametric Modeling suggests some common structures for parametric models, however, their structures are predominately focused on solving architectural design problems rather than addressing the problems of unstructured code. Accordingly, there remains significant scope to implement relatively straightforward structuring techniques on parametric models, which (based on evidence from similar interventions during the software crisis) may improve the understandability of parametric models.
The actual act of writing computer code is covered in Code Implementation [2.3.1], a subsection of Software Coding [2.3]. At first glance, writing code may seem worthy of a more prominent place in the SWEBOK.1999, especially given that writing code is one of the defining jobs of a software engineer. Yet, the positioning of Code Implementation [2.3.1] in such a minor category indicates how much ancillary knowledge goes into successfully writing code. This is an important observation when considering what architects need to learn in order to create a parametric model, and it is a point I will return to in the discussion (chap. 8.4) as I contrast the education of software engineers with the education of architects learning to use parametric models.
The Code Implementation [2.3.1] category also encompasses tools programmers use to write code. These tools, known as Integrated Development Environments (IDE), assist programmers by managing the compiling and debugging of code, as well as providing feedback to aid code comprehension (such as: pointing out possible coding errors, or explaining the meaning of a particular programming command). In contrast, Leitão, Santos, and Lopes (2012, 143) say “the absence of a (good) IDE” for parametric modelling “requires users to either remember the functionality or read extensive documentation.” They go on to say, “an iterative write-compile-execute cycle,” implemented in most parametric modelling environments, “results in non-interactive development” (2012, 143). These limitations in the tools architects use to create parametric models could be addressed by borrowing concepts like live-debugging, live-programming, and other innovations from the IDEs software engineers use.
Software Coding [2.3] has two additional sections: Reuse [2.3.2], and Standards and Documentation [2.3.3]. Both of these sections are related to Software Design [2.2]. Reuse [2.3.2] relates to how the program has been structured and particularly whether modules of code can be extracted and shared. The structure also plays a role in Standards and Documentation [2.3.3] since these are tied to the levels of abstraction in the structure. Both Reuse [2.3.2] and Standards and Documentation [2.3.3] help reinforce the importance of well-structured programs and give more impetus to investigate the structure of parametric models.
Software Testing [2.4] involves verifying code correctness. Programmers like to automate this process, either by using metrics for measuring performance [2.4.4], or by automated unit testing of the code itself [2.4.1, 2.4.2], or even with quantitative experiments like A/B testing user behaviour. Anecdotally, architects seem to test their models by manually verifying the outputs, which can lead to problems like change blindness (see chap. 2.3). Schultz, Amor, and Guesgen (2009, 402) demonstrate that testing methods “inspired by research in software engineering” may be applied to “qualitative spatial” problems. While there is considerable opportunity for further research in this area, given my focus on parametric model flexibility, I have elected to look only at Software Testing [2.4] in relation to measuring model flexibly with software metrics [2.4.4] (see chap. 4).
The final category in Software Product Engineering [2] is Software Operations and Maintenance [2.5], which embodies “concepts, methods, processes, and techniques that support the ability of a software system to change, evolve, and survive” (Hilburn et al. 1999, 25). In a similar manner, my research focuses on the change, evolution, and survival of both software and parametric models. In software engineering, the Software Maintenance Process [2.5.3] employs a “process [that] would include phases similar to those in a process for developing a new software product” (Hilburn et al. 1999). Thus, while Software Operations and Maintenance [2.5] is a distinct stage of Software Product Engineering [2], and a stage that closely resembles the goals of my research, the actual knowledge of operations and maintenance is already deployed in the prior stages of Software Product Engineering [2].
3. Software Management
Software Management [3] is the last major category of the SWEBOK.1999. Many of the same management challenges reoccur in software engineering and parametric modelling. These include more general challenges, such as managing a creative process whilst adhering to a budget, a schedule, and guarantees of quality; and these also include more specific challenges, like managing the development of code when the programming language requires precision but the outcome is uncertain. Accordingly, the management strategies employed by software engineers often have rough equivalence to strategies employed by architects. For example, the waterfall method has similar stages and a similar shift in effort to MacLeamy’s front-loading, and agile development has a similar pattern of iterative prototyping present in Schön’s reflective practice.
However, within these general areas of agreement, there are idiosyncrasies to the specific management practices of software engineers. In Software Quality Management [3.3] (which overlaps with Testing [2.4]), software engineers emphasise automated quantitative measures of quality, either through unit testing to validate the code or through metrics to measure code quality objectively (these are applied to parametric models in chapter 4.3). And in Software Process Management [3.5] there is a degree of formalism around the design processes that would be unfamiliar to most architects. For instance, in the Scrum development process (a popular form of agile development) the inventors, Jeff Sutherland and Ken Schwaber (2011, 6-10), specify everything from the number of days a design cycle should last (a month), to the ideal team size (less than nine people), to the length of daily meetings (fifteen minutes). Since these management processes are so tuned to the nuances of programming, further research is required to establish whether they also translate to the nuances of parametric modelling.
Whilst Software Management [3] is undoubtedly a ripe area of investigation in the context of parametric modelling, it is an investigation I will leave for others to undertake. I have decided to limit my thesis primarily to the study of Computer Fundamentals [1] and Software Product Engineering [2] because understanding these technical issues is quite different to understanding the ethnographic issues of management. Covering both inside one thesis is unlikely to do justice to either. For this reason I will touch on only some of the ideas in Software Management [3], notably around Software Quality Management [3.3], but it will not be a primary focus for the remainder of this thesis.
3.3 – Conclusion
The software crisis recalls many of the same challenges of parametric modelling. For software engineers, the improvements in computation during the 1960s resulted in more software being developed. The software was generally growing larger, being written in more abstracted languages, and running on-top better hardware. However, rather than programming becoming easier, these improvements intensified the difficulty of simply writing software (Wirth 2008, 33). Like architects working with parametric models, software engineers struggled to make changes within the logical rigidity of programming. These difficulties were amplified by the cost of change rising exponentially during a project – a phenomena highlighted by Boehm (1976; fig. 11) in a graph that resembles similar graphs by Paulson (1976; fig. 9) and MacLeamy (2001; fig. 10).
The software crisis gave rise to software engineering, a discipline dedicated to understanding the manufacture of software (Naur and Randell 1968, 13). Since demarcating this area of knowledge in the 1960s, software engineers have steadily become more successful at producing software (fig. 14; The Standish Group 1994 & 2012). Software engineers now postulate that that they can lower the cost of change to the point where the vertical asymptote of Boehm’s curve bends horizontal (fig. 13; Beck 1999, 27). Such radical transformations in software engineering arise from knowledge gained during decades of work studying the software engineering process.
The knowledge that has transformed software engineering is classified in the Software Engineering Body of Knowledge Version 1.0 (Hilburn et al. 1999). Somewhat surprisingly, the act of writing code occupies a very small sub-section [2.3.1] of this classification; a position that underscores the breadth of knowledge (besides simply knowing how to program) required for successfully developing software. Some areas of knowledge, like Software Management [3], have direct correlations to the design process. Other areas, like certain aspects of Computing Fundamentals [1], are so essential to anything involving a computer that architects already necessarily benefit from them. However, large portions of the SWEBOK.1999 are largely without precedent in the practice of parametric modelling. In this chapter I have identified a number of knowledge areas that are potentially applicable to parametric modelling while being accessible within the technical and temporal constraints of a PhD thesis. These are:
- 1.5 Programming Languages
- 2.2 Software Design
- 2.3 Software Coding
- 2.4 Testing
Programming Languages [1.5], Software Design [2.2], and Software Coding [2.3] are the respective focus of the three case studies in chapters 5, 6, & 7. Specifically, chapter 5 explores the impact of under-utilised Programming Paradigms [1.5.2], chapter 6 considers how the structure of Software Design [2.2] may apply to a parametric model, and chapter 7 investigates how Code Implementation [2.3.1] environments inform the development of parametric models. Each of these chapters aims to assess the influence the respective area of knowledge has on the flexibility of various parametric models. In order to measure flexibility, I draw upon the knowledge area of Testing [2.4], the focus of the following chapter.
Thesis Navigation
- Return to table of contents
- Goto previous chapter
- Goto next chapter
- Download entire thesis as PDF (30mb)
Footnotes
1:While computers are a relatively recent invention, their rapid development has left behind an immense history. In this chapter I only touch two aspects of this history: the software crisis and the cost of change curve. For a more complete history I would recommend starting with Wirth’s (2008) Brief History of Software Engineering, which references a number of the key papers. Unfortunately it seems no one has yet written a comprehensive book on history of software engineering – perhaps due to the size and speed of the industry – so beyond Wirth’s paper the best sources tend to be books and articles published from the period, such as Brook’s (1975) The Mythical Man-month. Numerous guides to the best literature can be found online.
2:Computers in 1968 were “becoming increasingly integrated into the central activities of modern society” (Naur and Randell 1968, 3) and many at the conference were concerned that software failures would come to harm those who were now relying upon computers.
3:I can find no evidence that Paulson or Boehm knew of each other’s work.
4:This includes: 3dsMax: Maxscript; Archicad: GDL; Autocad: AutoLISP; Digital Project: Visual Basic; Maya: Maya Embedded Language; Processing: Java; Revit: Visual Basic & Python; Rhino: Visual Basic & Python; Sketchup: Ruby.
5:This includes: Grasshopper; GenerativeComponents; Houdini; and MaxMsp.
6:Meyer (1997, 40-46) cites benefits to code decomposition, composition, understandability, continuity, and protection, which I will discuss in further in chapter 6.2.
Bibliography
ACM (Association for Computing Machinery). 2000. “A Summary of the ACM Position on Software Engineering as a Licensed Engineering Profession.” Unpublished report, 17 July.
Abran, Alain, and James Moore, eds. 2004. Guide to the Software Engineering Body of Knowledge: Version 2004. Los Alamitos: Institute of Electrical and Electronic Engineers Computer Society.
Aish, Robert, Benjamin Barnes, Mehdi Sheikholeslami, and Ben Doherty. 2012. “Multi-modal Manipulation of a Geometric Model.” US Patent application 13/306,730, filed 29 November 2011, and published 12 July 2012.
Appleby, Doris, and Julius VandeKopple. 1997. Programming Languages: Paradigm and Practice. Second edition. Massachusetts: McGraw-Hill.
Bagert, Donald, Thomas Hilburn, Greg Hislop, Michael Lutz, and Michael Mccracken. 1999. Guidelines for Software Engineering Education Version 1.0. Pittsburgh: Carnegie Mellon University.
Beck, Kent, Mike Beedle, Arie van Bennekum, Alistair Cockburn, Ward Cunningham, Martin Fowler, James Grenning, et al. 2001a. “Manifesto for Agile Software Development.” Published February. http://agilemanifesto.org/.
Beck, Kent, Mike Beedle, Arie van Bennekum, Alistair Cockburn, Ward Cunningham, Martin Fowler, James Grenning, et al. 2001b. “Principles behind the Agile Manifesto.” Published February. http://agilemanifesto.org/principles.html.
Beck, Kent. 1999. Extreme Programming Explained: Embrace Change. Boston: Addison-Wesley.
Boehm, Barry. 1976. “Software Engineering.” IEEE Transactions on Computers 25 (12): 1226-1241.
Boehm, Barry. 1981. Software Engineering Economics. Upper Saddle River: Prentice Hall.
Boehm, Barry. 1988. “A Spiral Model of Software Development and Enhancement.” Computer 21 (5): 61-72.
Brooks, Frederick. 1975. The Mythical Man-month : Essays on Software Engineering. Anniversary edition. Boston: Addison-Wesley.
Brooks, Frederick. 2010. The Design of Design: Essays from a Computer Scientist. Upper Saddle River: Addison-Wesley.
Böhm, Corrado, and Giuseppe Jacopini. 1966. “Flow Diagrams, Turing Machines And Languages With Only Two Formation Rules.” Communications of the Association for Computing Machinery 9 (5): 366-371.
Dijkstra, Edsger. 1968. “Go To Statement Considered Harmful.” Communications of the Association for Computing Machinery 11 (3): 147–148.
Dijkstra, Edsger. 1972. “The Humble Programmer.” Communications of the Association for Computing Machinery 15 (10): 859-866.
Dorfman, Merlin, and Richard Thayer. 1996. “Issues: The Software Crisis.” In Software Engineering, edited by Merlin Dorfman, and Richard Thayer, 1–3. Los Alamitos: IEEE Computer Society Press.
Díaz-Herrera, Jorge, and Thomas Hilburn, eds. 2004. Software Engineering 2004: Curriculum Guidelines for Undergraduate Degree Programs in Software Engineering. Engineering. Los Alamitos: Institute of Electrical and Electronic Engineers Computer Society.
Hilburn, Thomas, Iraj Hirmanpour, Soheil Khajenoori, Richard Turner, and Abir Qasem. 1999. A Software Engineering Body of Knowledge Version 1.0. Pittsburgh: Carnegie Mellon University.
Leitão, António, Luís Santos, and José Lopes. 2012. “Programming Languages for Generative Design: A Comparative Study.” International Journal of Architectural Computing 10 (1): 139–162.
Meyer, Bertrand. 1997. Object-Oriented Software Construction. Second edition. Upper Saddle River: Prentice Hall.
Microsoft. 2005. “Testing Methodologies.” Microsoft Developers Network. Published January. http://msdn.microsoft.com/en-us/library/ff649520.aspx.
Naur, Peter, and Brian Randell, eds. 1968. Software Engineering: Report on a Conference Sponsored by the NATO Science Committee. Garmisch: Scientific Affairs Division, NATO.
Paulson, Boyd. 1976. “Designing to Reduce Construction Costs.” Journal of the Construction Division 102 (4): 587–592.
Philipson, Graeme. 2005. “A Short History of Software.” In Management, Labour Process and Software Development: Reality Bites, edited by Rowena Barrett, 12-39. London: Routledge.
Piker, Daniel. 2011. “Using Kangaroo (Grasshopper Version) (DRAFT).” Accessed 19 November 2012. https://docs.google.com/document/preview?id=1X-tW7r7tfC9duICi7XyI9wmPkGQUPIm_8sj7bqMvTXs.
Royce, Winston. 1970. “Managing the Development of Large Software Systems.” In Proceedings of IEEE WESCON, 328–338.
Rutten, David. 2012. “Programming, Conflicting Perspectives.” I Eat Bugs For Breakfast. Published 1 April. http://ieatbugsforbreakfast.wordpress.com/2012/04/01/programming-conflicting-perspectives/.
Schultz, Carl, Robert Amor, and Hans Guesgen. 2009. “Unit Testing for Qualitative Spatial and Temporal Reasoning.” In Proceedings of the Twenty-Second International Florida Artificial Intelligence Research Society Conference, edited by Lane Chad and Hans Guesgen, 402–407. Florida: AAAI Press.
Schön, Donald. 1983. The Reflective Practitioner: How Professionals Think in Action. London: Maurice Temple Smith.
Sutherland, Jeff, and Ken Schwaber. 2011. “The Scrum Guide: The Definitive Guide to Scrum – The Rules of the Game.” White-paper. Scrum.org.
The Standish Group. 1994. “The CHAOS Report 1994.” White-paper. Boston: The Standish Group.
The Standish Group. 2012. “The CHAOS Report 2012.” White-paper. Boston: The Standish Group.
Wallner, Johannes, and Helmut Pottmann. 2011. “Geometric Computing for Freeform Architecture.” Journal of Mathematics in Industry 1 (1): 1-11.
Weisberg, David. 2008. “The Engineering Design Revolution: The People, Companies and Computer Systems that Changed Forever the Practice of Engineering.” Accessed 23 July 2011. http://www.cadhistory.net.
West, Dave, and Tom Grant. 2010. “Agile Development : Mainstream Adoption Has Changed Agility.” White-paper. Forrester.
Whitaker, William. 1993. “Ada: The Project, The DoD High Order Language Working Group.” ACM SIGPLAN Notices 28 (3): 229–331.
Wirth, Niklaus. 2008. “A Brief History of Software Engineering.” IEEE Annals of the History of Computing 30 (3): 32-39.
Woodbury, Robert, Robert Aish, and Axel Kilian. 2007. “Some Patterns for Parametric Modeling.” In Expanding Bodies: 27th Annual Conference of the Association for Computer Aided Design in Architecture, edited by Brian Lilley and Philip Beesley, 222–229. Halifax, Nova Scotia: Dalhousie University.
Woodbury, Robert. 2010. Elements of Parametric Design. Abingdon: Routledge.
Illustration Credits
- Figure 11 – Barry Boehm 1981, 40
- Figure 12 – Kent Beck 1999, 26
- Figure 13 – Kent Beck 1999, 28
- Figure 14 – Daniel Davis, based on: The Standish Group 1994 & 2012
- Figure 15 – Daniel Davis
- Figure 16 – Daniel Davis, based on: Appleby and VandeKopple 1997