
Cite as: Davis, Daniel. 2013. “Modelled on Software Engineering: Flexible Parametric Models in the Practice of Architecture.” PhD dissertation, RMIT University.
6.0 – Case B: Structured Programming
Project: Designing Dermoid.
Location: Royal Danish Academy of Fine Arts, Copenhagen, Denmark.
Project participants from SIAL: Mark Burry, Jane Burry, Daniel Davis, Alexander Peña de Leon.
Project participants from CITA: Mette Thomsen, Martin Tamke, Phil Ayres, Anders Deleuran, Aron Fidjeland, Stig Nielsen, Morten Winter, Tore Banke, Jacob Riiber; Workshop 3, Material Behaviour, Department 2, EK2, fourth year (November 2010); Workshop 4, Paths to Production, Department 2, third year, (January 2011).
Related publications:
Davis, Burry, and Burry, 2011a.
Davis, Burry, and Burry, 2011b.
6.1 – Introduction

Figure 43: Digital and physical models intermixed at the June 2010 Dermoid Workshop. From left to right: Martin Tamke, Jacob Riiber, Morten Winter, Jane Burry (hidden), Mark Burry, Alexander Peña de Leon, Phil Ayres, Mette Thomsen.
In June 2010 I found myself biking to the edge of Copenhagen, out past the Royal Danish Academy of Fine Art, and into a secluded concrete studio. The studio was filled with full-scale wooden prototypes, with laptops connected to various international power adaptors, and with researchers from CITA1 and SIAL2. The researchers were all debating a deceptively simple problem: how can we fashion a doubly curved pavilion from a wooden reciprocal frame. It is a question that would occupy a dozen researchers, including myself, for over a year; a question that would eventually led to the construction of the first Dermoid pavilion in March 2011.

Figure 45: Dermoid installed at the 1:1 Research By Design exhibition, March 2011, Royal Danish Academy of Fine Art, Copenhagen.
There are numerous reasons why Dermoid was so difficult. One source of difficulty was the unknowns in the brief: we did not know the shape of the pavilion’s doubly curved surface, or even where the pavilion would be built; and at the time no one could calculate the structural performance of a reciprocal frame, especially one constructed from a heterogeneous material like wood. There were also many known difficulties in the brief: uniformly patterning a doubly curved surface is notoriously hard, and the circular relationships of a reciprocal frame do not lend themselves to parametric modelling. Further adding to the difficulty, the project involved a diverse team situated at opposite ends of the earth. In short, it was a project destined to challenge even the most skilled designers, the ideal project to observe the inflexibility of parametric models.

Figure 44: Detail of Dermoid installed at the 1:1 Research By Design exhibition, March 2011, Royal Danish Academy of Fine Art, Copenhagen.
While Dermoid embodies many noteworthy innovations, in this case study I want to discuss specifically the development of Dermoid’s parametric models. The models have many authors since the researchers working on Dermoid were all experienced in parametric modelling, many of them world experts. The range of contributors meant that there was rarely a single “keeper of the geometry” – a name Yanni Loukissas (2009) gives to the person on a project who inevitably becomes solely responsible for the upkeep of the model. I assumed this role briefly as I prepared Dermoid’s parametric models for a workshop held in November 2010 at the Royal Danish Academy of Fine Arts. During this period I experimented with changing the structure of the models based on organisational techniques used by software engineers (identified in chapter 3.2). In this chapter I consider the impact of these changes using a combination of thinking-aloud interviews and observations of subsequent model development. I will begin by discussing the historic motivation that led software engineers to structure their code, and benefits they observed from doing so.
6.2 – Structured Programming
In March 1968, Edsger Dijkstra (1968) wrote a letter to the Association for Computing Machinery entitled Go To Statement Considered Harmful. At the time, the GOTO statement was the primary mechanism of controlling a computer program’s sequence of execution (the GOTO statement allows a program to skip ahead or jump backwards in a chain of programming commands). Dijkstra (1968, 148) argued that the intertwined jumps programmers were producing with GOTO statements were “too much an invitation to make a mess of one’s program.” Building on the work of Böhm and Jacopini (1966), Dijkstra proposed reducing the mess with simple structural commands such as if-then-else, and while-repeat-until. Although these structures now underlie all modern programming languages, they were not an obvious development in 1968. Many worried that structure would interrupt the “art” of programming (Summit 1996, 284), and that code would be even more difficult to understand when obscured by structure. Dijkstra (1968, 148) agreed and cautioned, “the resulting flow diagram cannot be expected to be more transparent than the original one.” Nevertheless, when scientists assembled at NATO a few months later in 1968 to discuss the impending software crisis – with Dijkstra in attendance – many of their conversations made reference to code structure (Naur and Randell 1968).3
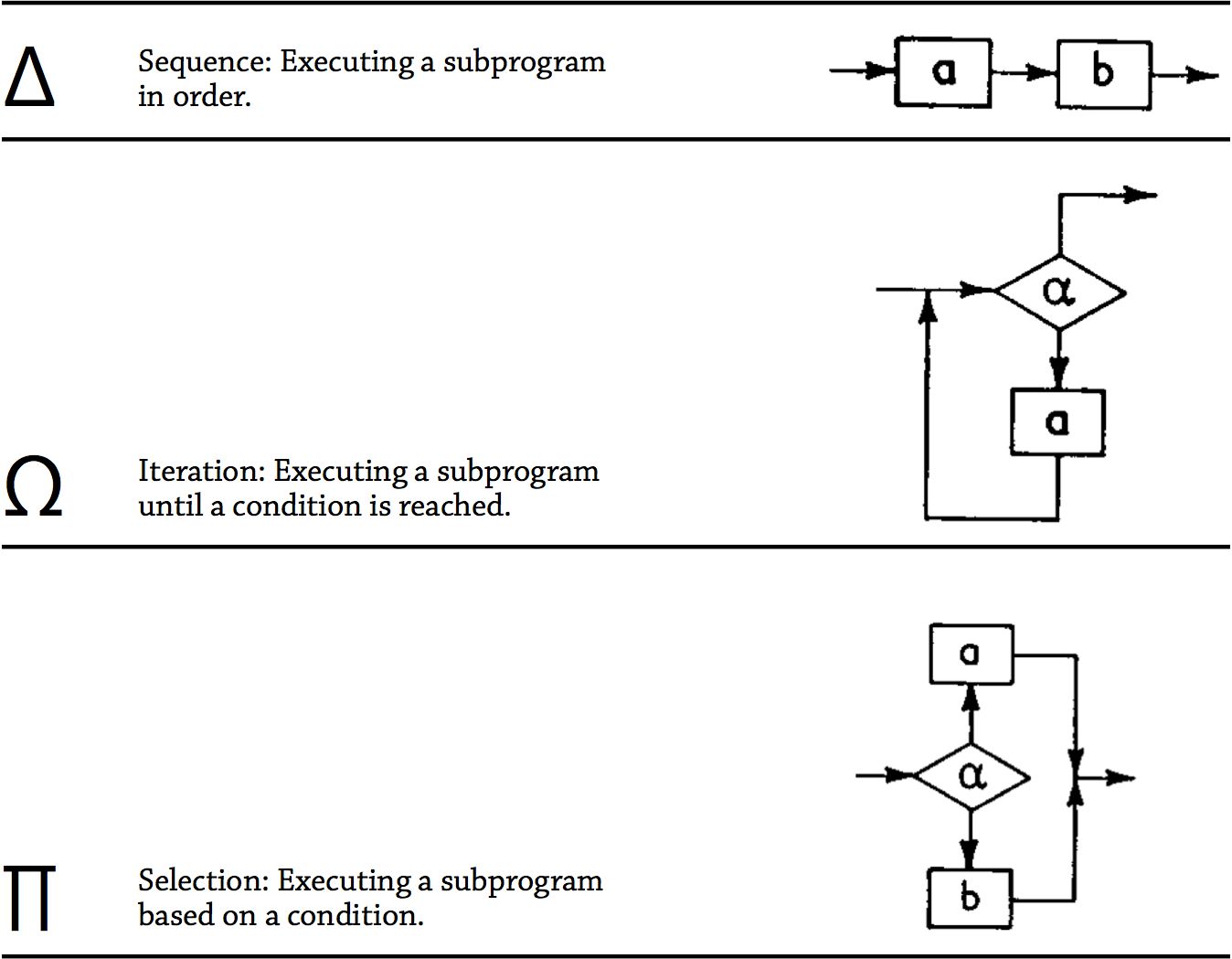
Figure 46: The three structures that Böhm and Jacopini (1966) proved could be combined to create a Turing machine.
While there was no single cure to the software crisis, structure is now recognised as an important remedy for taming what Bertrand Meyer (1997, 678) calls the “unmistakable ‘spaghetti bowl’ look” of tangled GOTO statements that undoubtedly contributed to parts of the crisis. There are many types of structure but Böhm and Jacopini’s (1966) original proof (referred to by Dijkstra) uses only three, which they represent by the symbols ∏, Ω, and ∆ (fig. 46). Böhm and Jacopini (1966) showed how these three structures could be combined, without the GOTO statement, to create Turing complete programs. The implication of their proof is that any unstructured program employing the GOTO statement can be rewritten without the GOTO statement by decomposing the program into a structure of subprograms that are linked using ∏, Ω, and ∆. Doing so eliminates the danger of stray GOTO statements jumping into unexpected locations. However, it took a lot more than a letter from Dijkstra for this proof to filter down into practice.4
Modules
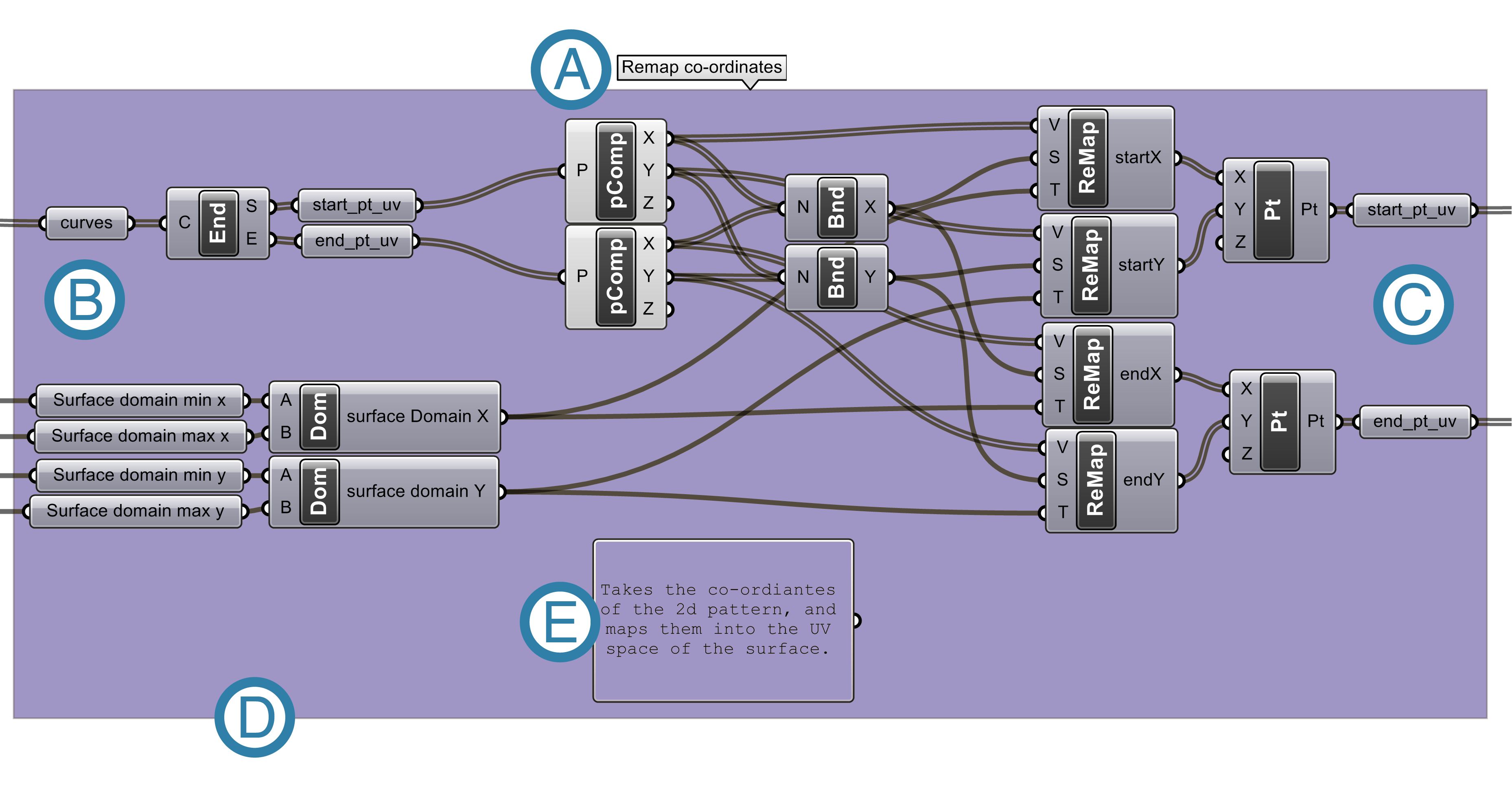
Figure 47: A typical module in Grasshopper. The grey boxes are operations (themselves small modules) that have been linked together to form a larger module. More recent versions of Grasshopper have native support for modules (which are called clusters in Grasshopper) however at the time of my research this version of Grasshopper had not been released. (A) The name of the module. (B) The inputs – the only place data enters the module. (C) The outputs – the only place data leaves the module. (D) The operations of the module are encapsulated so that they can only be invoked by passing data through the module’s inputs. (E) A description of what the module does – a module does one problem-related task.
The subprograms employed by Böhm and Jacopini have many synonyms in contemporary programming: methods, functions, procedures, and modules. Each term signifies the same general idea with a slightly different overtone. I have chosen to use the word module because of the connotations with standardisation, reuse, self-containment, and assembly (themes I will explore further in this chapter). A module is defined by Wong and Sharp (1992, 43) as “a sequence of program instructions bounded by an entry and exit point” that perform “one problem-related task” (these principles are applied to a module in Grasshopper in figure 47). If employed successfully, modules have five principle benefits according to Bertrand Meyer (1997, 40-46):
- Decomposition: A complicated problem can be decomposed into a series of simpler sub-problems each contained within a module. Decomposing problems like this may make them easier to approach and may make it easier for teams to work together since each team member can work on a separate sub-problem independently.
- Composition: If modules are adequately autonomous they can be recombined to form new programs (a composition). This enables the knowledge within each module (of how to address a sub-problem) to be shared and reused beyond its original context.
- Understandability: If a module is fully self-contained, a programmer should be able to understand it without needing to decipher the overall program. Conversely, a programmer should be able to understand the overall program without seeing the implementation details of each individual module. Dijkstra (1968, 148) worried this would lead to less transparency but most have since argued that abstraction helps understandability. For instance, Thomas McCabe (1976, 317) has posited that modularisation improves understandability since it reduces the cyclomatic complexity, making it “one way in which program complexity can be controlled.” Meyer (1997, 54) points out that modularisation aids a programmer’s comprehension of the code through the names given to inputs, outputs, and the module itself.
- Continuity: A program has continuity when changes can be made without triggering cascades of other changes. In a program without continuity, changing one module will affect all the dependent modules, setting off a chain-reaction as all the dependent modules are changed to accommodate the original change and so on. Continuity has much to do with how a program’s structure is decomposed. David Parnas (1972, 1058) suggests that projects should be broken around “difficult design decisions or design decisions which are likely to change” so that each anticipated change is contained within a module in such a way that it does not impact the other modules.
- Protection: Each module can be individually tested and debugged to ensure it works correctly. But if something does go wrong within a module, the module can contain the error and thwart its propagation throughout the program (protecting the rest of the modules from the error).
The benefits of modularisation are so pervasive that some modern programming languages, like C# and Java, make it impossible to write code not contained within some sort of module. Java even stopped supporting the GOTO statement, and some of the more recently invented languages – like Python and Ruby – have never supported the GOTO statement.5 In its place are screeds of structural constructs, from switch-case, to try-catch, to polymorphic objects. These structures, like Böhm and Jacopini’s original three, offer programmers various ways to decompose and recompose programs from smaller, self-contained chunks. Debates continue about how best to wield structure in order to increase understandability and reduce complexity, whilst improving continuity and protection. These debates fill entire sections of libraries and occupy the Software Design [2.2] section of the Software Engineering Body of Knowledge Version 1.0 (Hilburn et al. 1999, 20). Yet despite the pervasive benefits of modularisation, architects creating parametric models in visual programming languages still tend to create unstructured models, as I will show in the following section.
6.3 – Architects Structuring Visual Programs
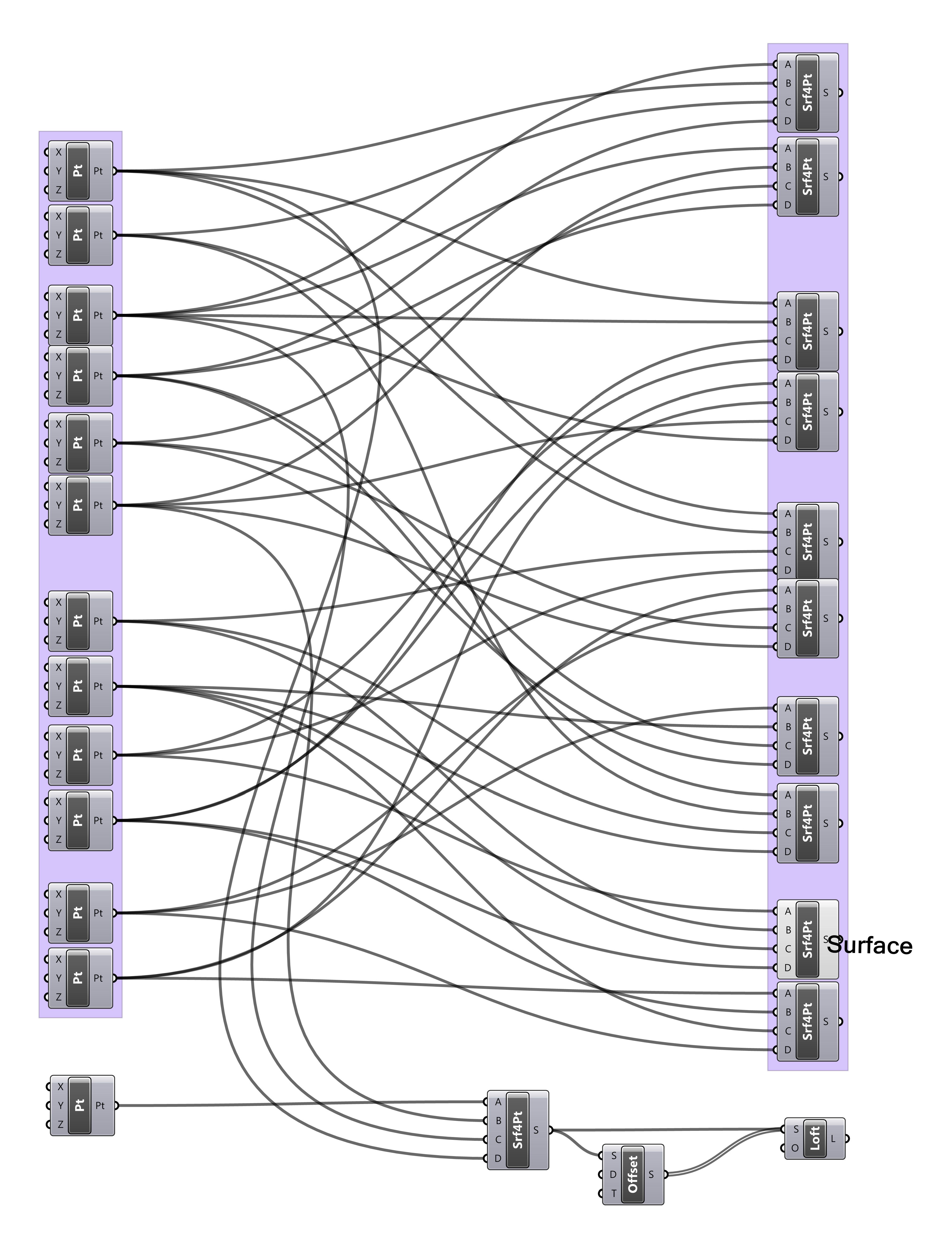
Figure 48: Examples of spaghetti forming in two unstructured Grasshopper models. Neither model gives any hint (through naming or otherwise) as to what the crisscrossed connections do and it is impossible deduce simply from inspection.
Unlike the programming languages in the 1960s, which were unstructured simply because the syntax for structure had not been invented, all the major visual programming languages used by architects have some basic structural constructs. In particular, they all support modularisation. In the lexicon of the various software, modules have come to be known as features in Bentley’s GenerativeComponents, digital assets in Sidefx’s Houdini, and clusters in McNeel’s Grasshopper. But even though these modular constructs exist, architects tend not to use them. In chapter 4.3’s sample of 2002 Grasshopper models, 97.5% of the models did not employ modules.6 Moreover, 48% of models had no modules, no groups, no explanation of what they did, and no naming of parameters: by even the most generous of definitions these models were completely unstructured.7 In addition to being unstructured, the models generally have a high cyclomatic complexity (see chap. 4.3) and possess what Meyer (1997, 678) calls the “unmistakable ‘spaghetti bowl’ look” of interwoven relationships and long chain dependencies (fig. 48). In many ways these tangled visual programs parallel the knots of GOTO statements that characterised the programs of the 1960s, with seemingly similar consequences in terms of understandability. It remains unknown precisely why architects are creating models that are seemingly so messy, complicated, and unstructured. Two possible explanations are that the Grasshopper implementation of modules is somehow flawed, or that architects lack the knowledge required to utilise the modules properly.8
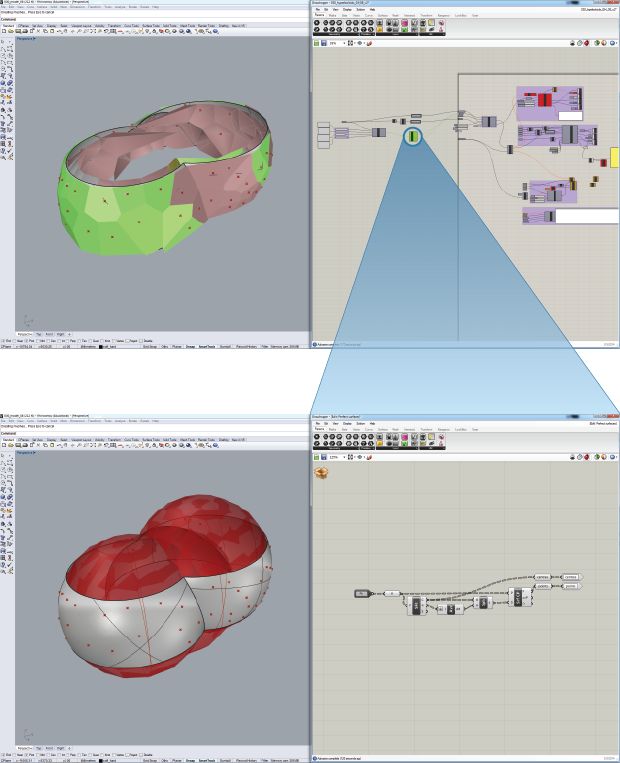
Figure 49: A cluster in Grasshopper (a model used in chapter 7 for the FabPod). Top: The full parametric model with the cluster in its most abstract form. Bottom: Opening the cluster to reveal the operations it encapsulates, however, opening the cluster also hides the rest of the model, which impedes the model’s visibility and juxtaposability.
Implementation of Clusters
The low use of modules may be in part an artefact of Grasshopper’s cluster implementation. Clusters were a feature present in early versions of Grasshopper that was later removed in version 0.6.12 and subsequently reintroduced in version 0.8.0. The inconsistent presence and function of clusters undoubtedly makes some users untrusting of them.
Perhaps more significantly, however, the way clusters are currently implemented in Grasshopper may actually impede the understandability of the model.9 As Dijkstra (1968, 148) warned, structure can make the resulting program less “transparent than the original one.” While the abstraction brought about by less transparency may be beneficial in a textual language, in a visual language structural abstractions can hinder access to code according to Green and Petre (1996, 164). Their widely cited research on the usability of visual programming languages indicates that the understandability of a program is dependent upon visibility (how readily parts of the code can be seen) and juxtaposability (the ability to see two portions of code side-by-side) (Green and Petre 1996, 162-164). Clusters in Grasshopper constrain visibility by limiting the view to one particular level of abstraction at a time (fig. 49). Juxtaposability is currently impossible in Grasshopper since two levels of abstraction cannot be seen at the same time, or side-by-side. Furthermore, cluster reusability is impeded since cluster changes do not propagate through related instances of reused clusters. Owing to these limitations, the clusters in Grasshopper are more suited to packaging finalised code rather than supporting the decomposition and composition of an evolving program (the way structure is typically used in textual programs). This may be one reason for low cluster use in Grasshopper.
Structure and Education
Another possible factor leading to low cluster use has to do with the education of architects. Designers are generally not taught about parametric modelling as much as they are taught to use parametric modelling software.10 Woodbury (2010, 8) observes that most manuals and tutorials teach students by “providing lists of commands or detailed, keystroke-by-keystroke instructions to achieve a particular task.” For example, a student learning to use Grasshopper may start with the Grasshopper Primer (A. Payne and Issa, 2009). On page twenty-seven they learn how selecting seven items from the menu and linking them together produces a spiral through points, which is a lesson that is not substantively different to learning how selecting two items from the menu in the non-parametric software, Rhino, will also produce a spiral through points. This pedagogy continues throughout the Grasshopper Primer and in other Grasshopper introductions like Zubin Khabazi ’s (2010) Generative Algorithms using Grasshopper as well as in the teaching material for other parametric modelling software like Bentley Systems’ (2008) GenerativeComponents V8i Essentials and Side Effects Software’s (2012) Houdini User Guide. Students using these various guides are primarily taught the particular sequence of interface actions to make a tool that produces a particular geometric outcome, almost always without being taught the accompanying abstract concepts like program structure.
This parametric modelling pedagogy contrasts sharply with how programmers are taught. In chapter 3.2 I showed how the basic skill of programming (knowing the particular sequence of interface actions to produce a particular outcome) forms only a small part of the Software Engineering Body of Knowledge Version 1.0 (Hilburn et al. 1999). Programming is therefore only a small part of what entry level programmers are expected to know. Even resources designed to teach the basic skill of programming cannot help but discuss more abstract structural concepts – for instance, the fifth, sixth, and seventh chapters of Beginning Python (J. Payne 2010) respectively cover the following: creating subprograms and functions; creating classes and objects; and structurally organising programs.11 Structure is such an intrinsic part of programming that it is mandatory in some languages, like Java and C#, a concept reinforced in the practice of programming and fundamental to the education of programmers.
For architects, the most comprehensive analysis of structuring parametric models comes from Woodbury, Aish, and Kilian’s (2007) paper, Some Patterns for Parametric Modeling, which was later republished as a sizeable part of Woodbury’s (2011) Elements of Parametric Design. The paper riffs on the seminal software engineering book Design Patterns by Gamma, Helm, Johnson, and Vlissides12 (1995), although each has a slightly different emphasis: Design Patterns focuses on methods of structuring code to address problems with the code itself (such as reusability, understandability, and extendability), whereas Some Patterns for Parametric modeling presents patterns that solve problems specific to architecture (such as ordering points, projecting geometry, and selecting objects). This makes Some Patterns for Parametric Modeling more like a recipe book of useful modules than a Design Patterns-esque guide for structuring programs.
One pattern from Some Patterns for Parametric Modeling does address problems with the understandability of code itself. The Clear Names pattern advocates always naming objects with “clear, meaningful, short and memorable names” (Woodbury 2010, 190). This is a relatively easy pattern to follow in Grasshopper since the names of parameters can be quickly changed by clicking on them. Yet neither of the training manuals provided on the official Grasshopper website teach architects the clear names pattern. The only reference in Generative Algorithms Using Grasshopper comes from a caption that mentions “I renamed components to point A/B/C by the first option of their context menu to recognize them easier [sic] in canvas” (Khabazi 2010, 11). Similarly, the only reference in the Grasshopper Primer is half a sentence mentioning that designers can “change the name to something more descriptive” (A. Payne and Issa 2009, 10), without explaining how or why they should. Not surprisingly, 81% of the Grasshopper models I sampled contained no uniquely named parameters. This absence of basic modifications that improve the understandability of models may be a symptom of how architects are taught to model. While programmers learn about structure in basic books like Beginning Python and in dedicated books like Design Patterns, even simple concepts like naming parameters cannot be found in the educational material given to architects. This may be one reason that more advanced structural techniques (like modules) are so infrequently used by architects.
To Understand Visual Programs Better
The benefits of structured programming are undebatable for contemporary software engineers; it is something all programmers do, something some languages mandate, something covered in even basic introductions to programming. Despite the strong evidence in software engineering that structure is beneficial, we know very little about how the structure of parametric models affects the practice of architecture. We do know that architects tend not to structure their models, with two possible factors being both the education of architects and the way modules are implemented in parametric software. In this case study I consider what happens if these two impediments are removed and an architect structures their model. In particular I examine whether overcoming such impediments would be a worthwhile pursuit for architects. I have spread these considerations over a series of three experiments related to structuring the parametric models of the Dermoid pavilion:
- Evaluating the understandability of structured programs through thinking-aloud interviews [6.4].
- Analysing Dermoid’s modular model structure and how this affected the project development [6.5].
- Consideration of how parts of Dermoid can be recomposed and shared with the internet [6.6].
6.4 – Understandability of Visual Programs in Architecture
To discern whether structuring a parametric model impacts an architect’s comprehension of the model, I conducted an experiment whereby architecture students were shown a series of structured and unstructured visual programs. Using a thinking-aloud interview technique I established how legible the students found models with and without structure, thereby articulating what architects may or may not be missing when they create visual programs devoid of structure.
Method
Thinking-aloud interviews are a type of protocol analysis commonly used in computer usability studies as a means of understanding a user’s thought process as they carry out a task (Nielsen 1993, 195-200; Lewis and Rieman 1993, 83-86). Clayton Lewis pioneered the technique while working at IBM, a technique he plainly describes as “you ask your users to perform a test task, but you also ask them to talk to you while they work on it” (Lewis and Rieman 1993, 83). Users are typically asked to discuss the “things they find confusing, and decisions they are making” (Lewis and Rieman 1993, 84). As participants answer these questions they hopefully give the researcher an insight into their experience of performing the tasks; insights that would otherwise be concealed if the researchers only examined the participants actions, or only asked the participants point-blank, how easy was this task?
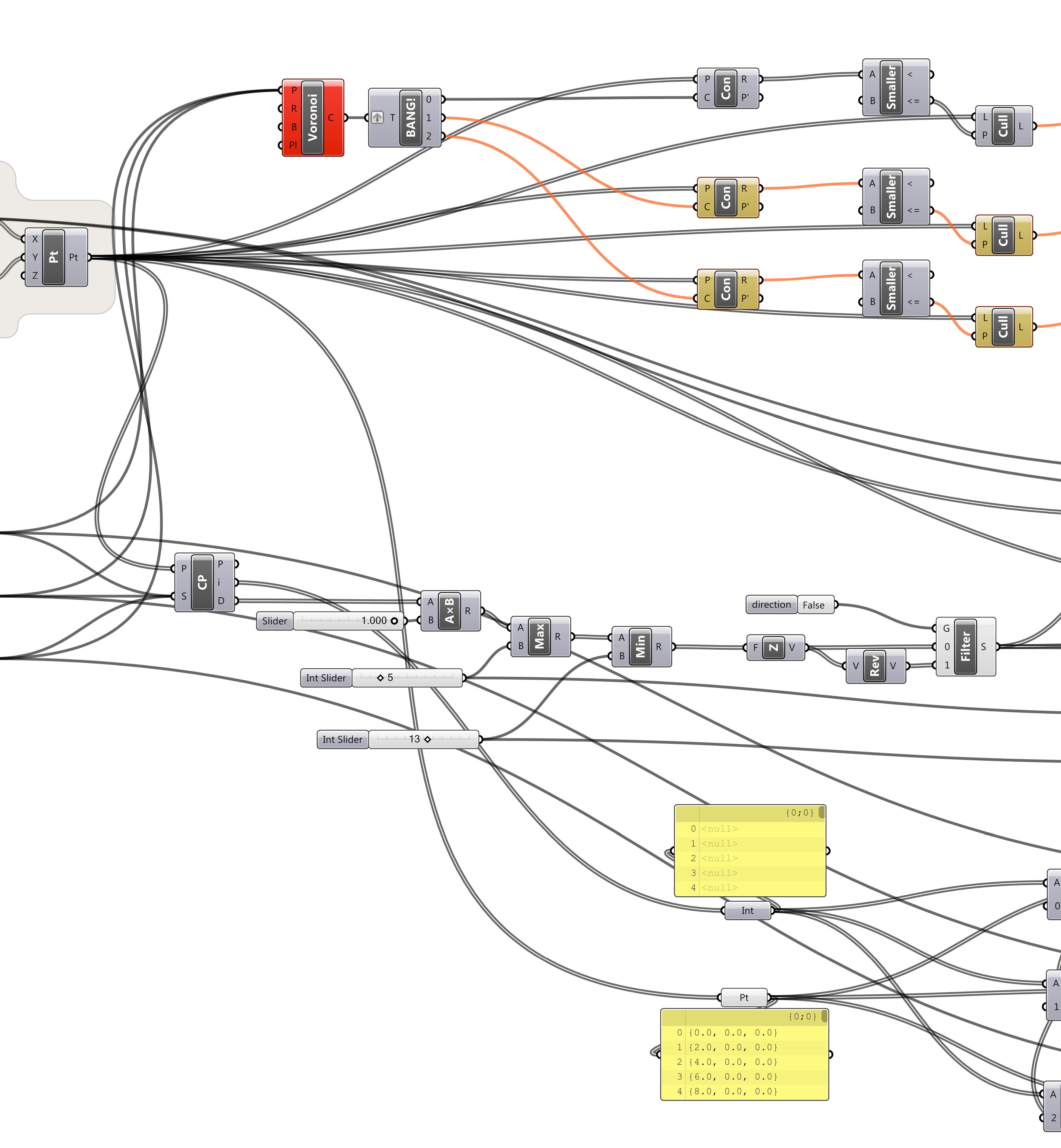
The participants were randomly selected from a class of twenty-five architecture students from the Royal Danish Academy of Fine Art who were attending a weeklong parametric modelling workshop. Four students were selected based on usability expert Jakob Neilson’s (1994, 249-56) recommendation to use between three and five participants in thinking-aloud interviews. The selected students each had between one and seven years’ experience with computer-aided design, and all had one year’s experience using Grasshopper – making them competent users but by no means experts. Each participant was shown three Grasshopper models in a prescribed order (fig. 50). For every model presented, the participant was set the task of describing how the model’s inputs controlled the model’s geometry (which was hidden from view) while talking-aloud about their reasoning process. This essentially placed the participants in a role similar to a designer trying to understand a parametric model a colleague had shared with them. The participants were free to explore the model by dragging, zooming, and clicking on screen.
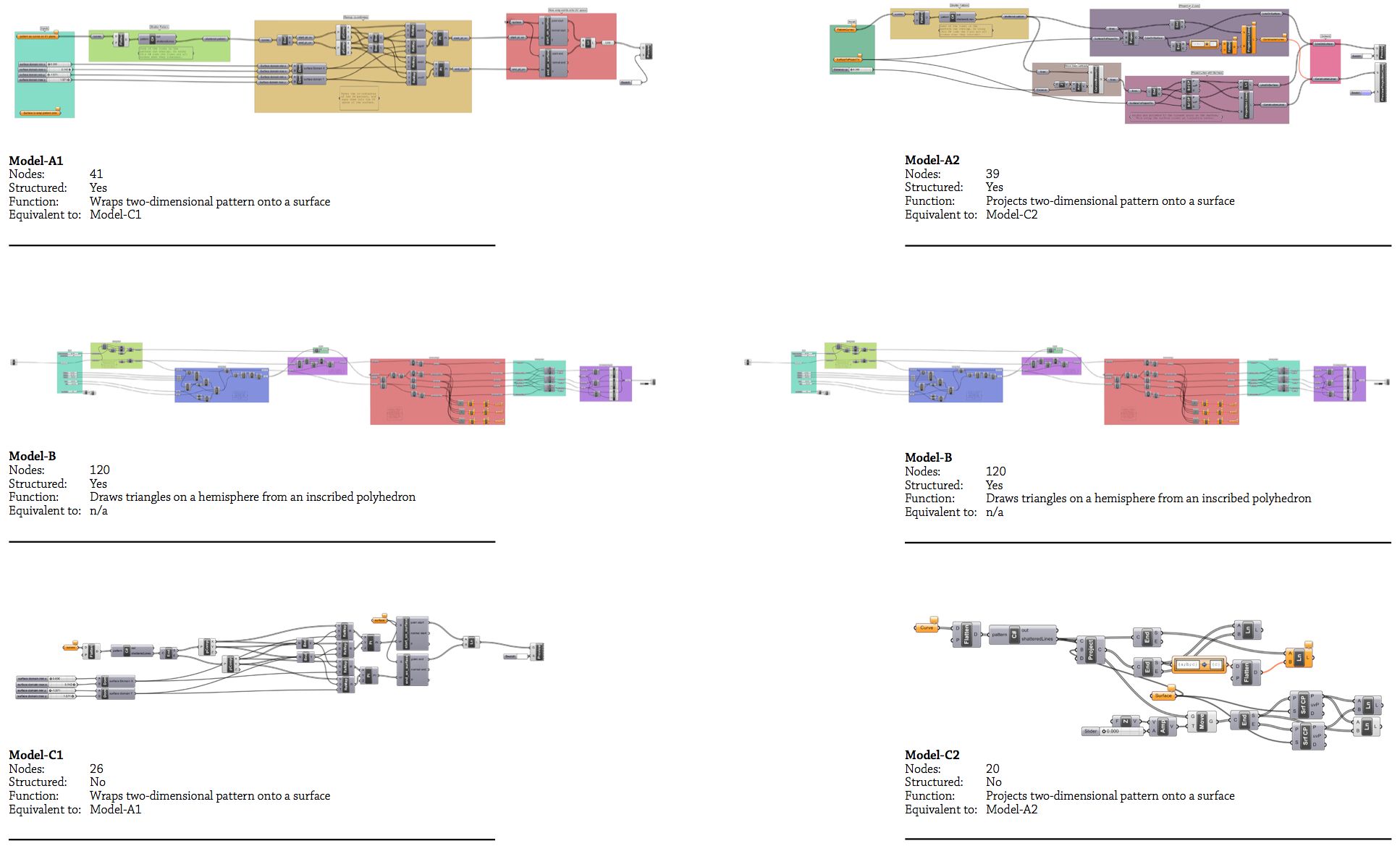
Figure 50: The Grasshopper models shown to the participants (click for detail). To reduce the bias from one model being uncharacteristically understandable the participants were either shown the three models on this page or the three models on the facing page (selected at random). The first model the participants saw, model-A, was a structured versions of the last model the participants saw, model-C. These models were of an average size (see chap. 4.3) and did a task the participants were generally familiar with (applying two-dimensional patterns to three-dimensional surfaces). To mask the fact that model-A and model-C were equivalent, the participants were shown model-B in between, which was much larger and did a task the participants were unfamiliar with (to ensure the participants spent a long time studying the model and forgetting about the first model). As the experiment was conducted at a time when Grasshopper did not support clusters, the structure was generated through visually separating groups of code around defined entry and exit points, and through clearly naming parameters and groups. Fortuitously this avoids some of the aforementioned issues of visibility and juxtaposability present in Grasshopper’s current cluster implementation.
Unbeknownst to the participants, the only difference between the first model they saw (model-A) and the last model they saw (model-C) was the structure of the two models. This allowed me to observe a designer reading a structured model and then reading again the unstructured version of the same model. I was then able to compare how structure affected the understandably of the two models. To mask the similarities of the first and last model, the participants were shown a much larger model (model-B) in between seeing the structured model-A and its unstructured equivalent, model-C. None of the participants realised they had been shown two versions of the same model.
Thinking-Aloud Results
When shown the structured model (model-A) the participants could all describe the model’s overall function. They had no problems identifying the inputs or outputs, and half could describe what occurred in each of the model’s major stages. When asked about individual nodes, the participants generally understood what each node did but on occasion they would struggle to explain the precise outcome of a particular node within its context.
In contrast, when shown the same model in unstructured from (model‑C) all the participants resorted to guessing the model’s function (none guessed correctly). A typical comment from Participant-2 was: “It relaxes the lines? That’s a guess though, because I am not sure what any of these elements [nodes], I am not sure what any of them do.” In reality all the participants knew what each node did; when asked about individual nodes they would be able to say things like “it [the node] makes a line that joins two points.” What Participant-2 was struggling with – like all the participants – was assembling this understanding of individual nodes into an understanding of the aggregate behaviour of all the nodes. With no structure to guide them, the participants often missed important clues like identifying the model’s inputs. No participant even realised they were being shown an unstructured version of the model they had seen earlier – all were surprised when told afterwards.
That participants should find structured models more understandable than unstructured models is hardly surprising given the aforementioned practices of software engineers. Yet it is surprising to see how relatively incomprehensible unstructured models – even small ones – are to designers unfamiliar with them. Even the much larger model-B was better understood by the participants than the small and unstructured model‑C. Despite model-B’s size and fairly obscure function, the participants could all methodically move through the nodes in each module describing them in far better detail than they could with model-C (although their understanding was not as comprehensive as with model-A). While size seems to invite complexity (see chap. 4.3), it seems that structure largely determines a model’s legibility.
The structured models had a number of key elements that seemed to guide the participant’s comprehension:
- Names: Participants regularly referred to node names and module names as they explained the model. This reinforces the Clear Names design pattern advocated by Woodbury (2010, 190). While naming nodes is relatively easy in Grasshopper, in the sample of 2002 Grasshopper models, only 19% of the models had one or more nodes that named a branch of data.
- Positioning: Participants often overlooked critical input nodes and output nodes in model-C since the unstructured model had all the nodes intermixed. Yet in the structured models (where all the inputs were to the left and all the outputs to the right) the participants could readily identify the inputs and outputs.
- Explanations: Some of the modules inside model-A and model-B contained short explanations of what they did. Participants seldom took the time to read these, which indicates a self-documenting model (one with clear names and a clear structure) is preferable to one explained through external documentation.
- Grouping: Two participants cited the grouping of nodes, and particularly how they were coloured, as a major aid. As with naming nodes, grouping nodes is relatively easy in Grasshopper, but it is not done by the majority of users (70% of the 2002 sampled models had no groups in them).
Factors in Understandability
There are different theories about how programmers come to understand code (Détienne 2001, 75) but all agree it is fundamentally a mapping exercise between the textual representation and the programmer’s internal cognitive representation. While the precise mechanisms of this mapping remain hidden, Green and Petre (1996, 7) observe that “programmers neither write down a program in text order from start to finish, nor work top-down from the highest mental construct to the smallest. They sometimes jump from a high level to a low level or vice versa, and they frequently revise what they have written so far.” This jumping between levels corroborates with Meyer’s (1997, 40-43) suggestion that structure helps programmers both to decompose high level ideas into smaller concepts, and to compose smaller parts into larger conglomerates. Yet my research has shown that the vast majority of architects neither compose nor decompose, they instead arrange components at one fixed level of abstraction. Architects presumably have in mind an overall notion of how the model works, but it seems without structure this overall perspective is lost along with the model’s legibility to designers who did not create the model. Designers are left to deduce a model’s overall behaviour solely through understanding the interaction of the model’s parts, which is an inference that none of the participants I observed came close to making.
The key finding of these thinking-aloud interviews is that designers find mapping between unstructured representations and their own internal cognitive representations difficult, if not impossible. Structure does not just make these mappings easier, it largely determines whether they can be done at all. This is a concerning finding in light of how infrequently architects structure their models. Most designers could introduce structure with a few key alterations, the most effective of which seem to be: clearly naming parameters, grouping nodes together, and providing clearly defined inputs and outputs. These alterations seem to help communicate the model’s intention, making it vastly more understandable for designers unfamiliar with the model. In the following section I will discuss the impact of making these alterations to parametric models used in an architecture project.
6.5 – Structured Programming in Practice
Dermoid
By the third Dermoid workshop (in November 2010; fig. 51), the project team had a decided that Dermoid would consist of reciprocal hexagons formed from cambered wooden beams weaving under and over a guiding surface. The rationale for this structure is discussed in greater detail by Mark Burry (2011) in Scripting Cultures but for the purpose of the present discussion, suffice to say, the chosen design direction presented numerous modelling challenges. By the November workshop there were still many unknowns, including, the shape of the surface, the details of the beam joints, and the overall structural performance. These would remain unknown until days before the construction commenced in March 2011 (having been calculated progressively through a series of physical modelling experiments). The unknowns suited the flexibility of parametric modelling, yet the reciprocal frame did not lend itself to parametric modelling since distributing a pattern on a doubly curved surface is a difficult problem made harder in this instance by the circular relationships of the reciprocal frame (which lend themselves to iterative solving rather than the linear progression of a parametric model). Thus, while months of work had occurred prior to the November workshop, most parts of the parametric model were still up for negotiation and required a degree of flexibility. I took the lead in developing the models for this stage of the project. In order to achieve the needed flexibility, I experimented with structuring the models. Doing so allowed me to consider the practicalities of structuring parametric models during a design project, and it also allowed me to observe how the structured models evolved once I handed them to other team members.
Structuring the Project
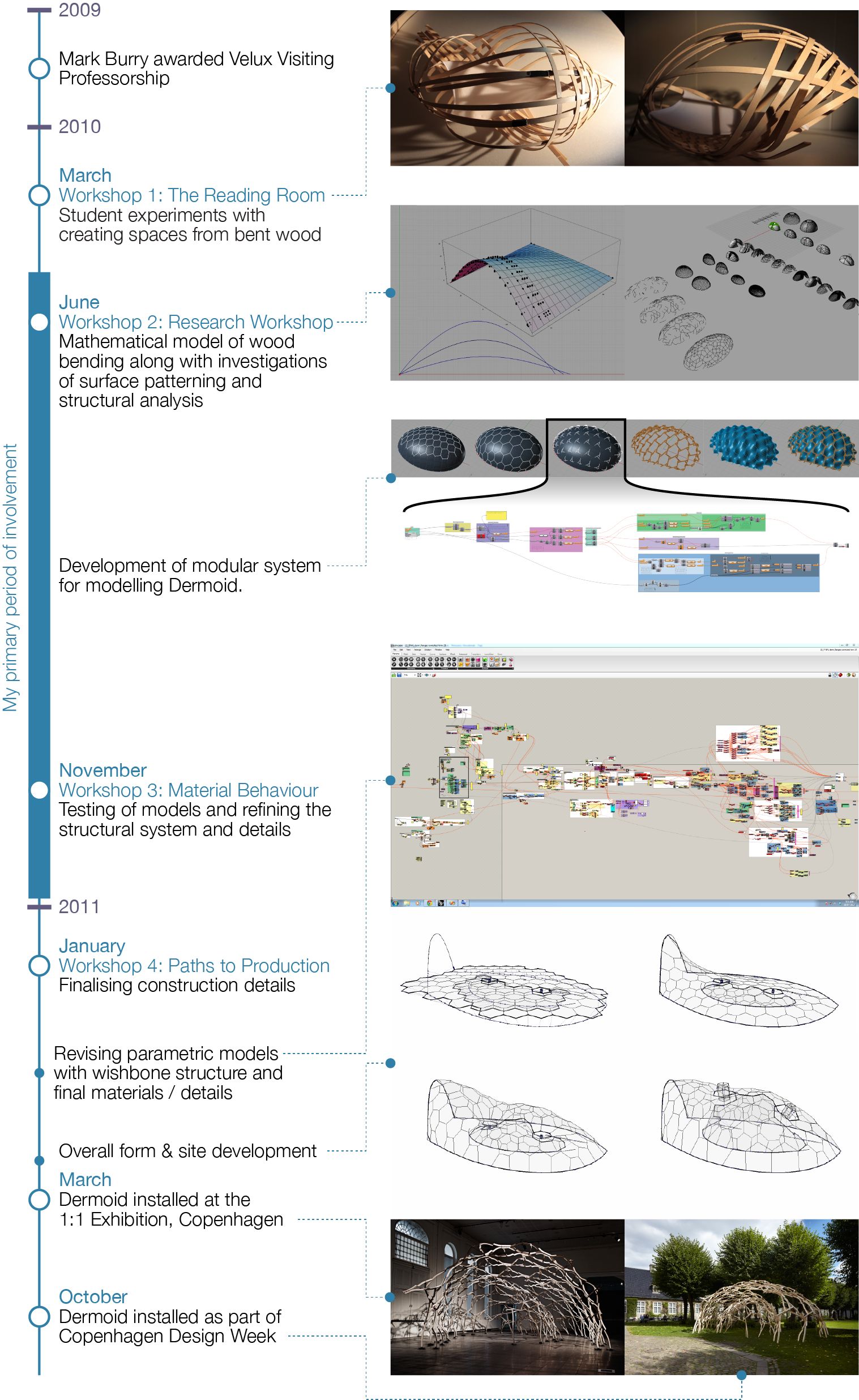
Figure 51: Key milestones in the development of Dermoid. Unlike a traditional design process, Dermoid’s design commences with investigations into the material properties of wood, and proceeds through detailing and design development, before concluding with a sketch of the form. This process is enabled to a large degree by the flexibility of the parametric models.
In the months prior to the November workshop, a number of key modelling tasks emerged as areas of research:
- Distributing the pattern evenly over the doubly curved surface.
- Calculating the intersection points of the reciprocal frame.
- Shaping and detailing the beams.
In a conventional linear design process, these considerations would come as part of Design Development or Detailed Design. It is of significance that they should be the early stages of Dermoid’s design process (fig. 51). The dissociation with the orthodox design progression carries through to other stages of Dermoid’s design where, for example, the construction documentation was produced prior to finalising the overall form. While changing a project’s form after generating the construction documentation would ordinarily be extremely disruptive and time consuming, the flexibility of Dermoid’s parametric models accommodated these types of late changes relatively effortlessly. In many ways this is the antithesis of Paulson and MacLeamy’s front-loading (see chap. 2.2): rather than forcing designers to make critical decisions early in a project as a means to avoid expensive design changes, in Dermoid the cost of change is lowered to the point where critical decisions can be delayed until the designers best understand the consequences of these decisions – even if this means delaying a decision until almost the end of a project. The flexibility of Dermoid’s parametric models essentially compressed the design cycle, allowing conceptual decisions to manifest quickly in construction documentation, allowing critical decisions to be delayed, and allowing the design process to begin with considerations not conventionally explored until later in the project.

Figure 52: The outputs from the chain of parametric models that generate Dermoid.
The project team developed a number of parametric models prior to the November workshop as they explored the three initial areas of research – pattern distribution, intersection points, and beam details. These models naturally form a chain (fig. 52) that progressively generates Dermoid, beginning with a two-dimensional pattern (Stage-A) and ending with the construction documentation (Stage-E2). Each stage in this chain can be thought of as a module since each has a prescribed set of inputs (from the previous stage) and a distinct set of outputs (for the next stage). The demarcations of these modules was not something imposed at the start of the project, rather they naturally emerged and crystallised around the volatile points of the project (pattern distribution, Stage-A, B & C; intersection points, Stage-D; beam details, Stage-E2). In hindsight the structure follows David Parnas’s (1972, 1058) advice to decompose projects around “difficult design decisions or design decisions which are likely to change.” By decomposing Dermoid around key points of research, each research question had a respective parametric model that could change to accommodate research developments. Provided any new parametric model outputted all of the stage’s requisite data, changing the parametric model would not disrupt the overall project. This allowed the team members to work concurrently on different aspects of the project without interfering with each other’s work. The structure was also software agnostic provided each model returned the right outputs. This proved useful on wicked stages (Rittel and Webber 1973) like pattern distribution (Stages B & C) where the stage’s parametric model was rebuilt in at least five different software packages during the course of the design. Being able to modify stages of a project without disrupting the overall project is described by Meyer (1997, 40-46) as continuity. Although breaking a parametric model into six stages and manually feeding data between them may seem intuitively less flexible than using a single parametric model, the continuity offered by decomposing Dermoid into six distinct stages helped improve the project flexibility by facilitating team-work and by helping make changes less disruptive.
Structuring the Models
Figure 53: A section of the parametric model from Stage-D, which demonstrates the structure of the models used in the November Dermoid workshop.
I began experimenting with structuring the models driving Dermoid as I prepared them for the November workshop (fig. 53). The models had initially been created in an unstructured way. To add structure I normally had to do the following: prune the branches of code not contributing to the model’s outcome; add new nodes to name paths of data clearly; and group the nodes into modules by looking for places where the data was naturally channelled into one or two streams. Software engineers call this process of restructuring code, refactoring. By beginning with unstructured code that I later refactored into a structured model I perhaps missed out on using structure as a compositional and decompositional design aid (Meyer 1997, 40-46), or as Green and Petre (1996, 7) put it, the “jumps from a high level to a low level or vice versa”. While I normally follow the practices described by Meyer, Green, and Petre when writing textual code, I found it difficult to use structure as a guide to create these visual programs. I have experimented with teaching architecture students to create visual programs guided by the structure of Input-Process-Output diagrams (Davis, Salim, and J. Burry 2011). While this method has had modest success, particularly at getting students unfamiliar with programming to think algorithmically, structured programming still feels forced in the visual programming environment of Grasshopper. This preference for structure through refactoring unstructured models may be tied to how structure is implemented in Grasshopper, as I discussed earlier.
After Structure
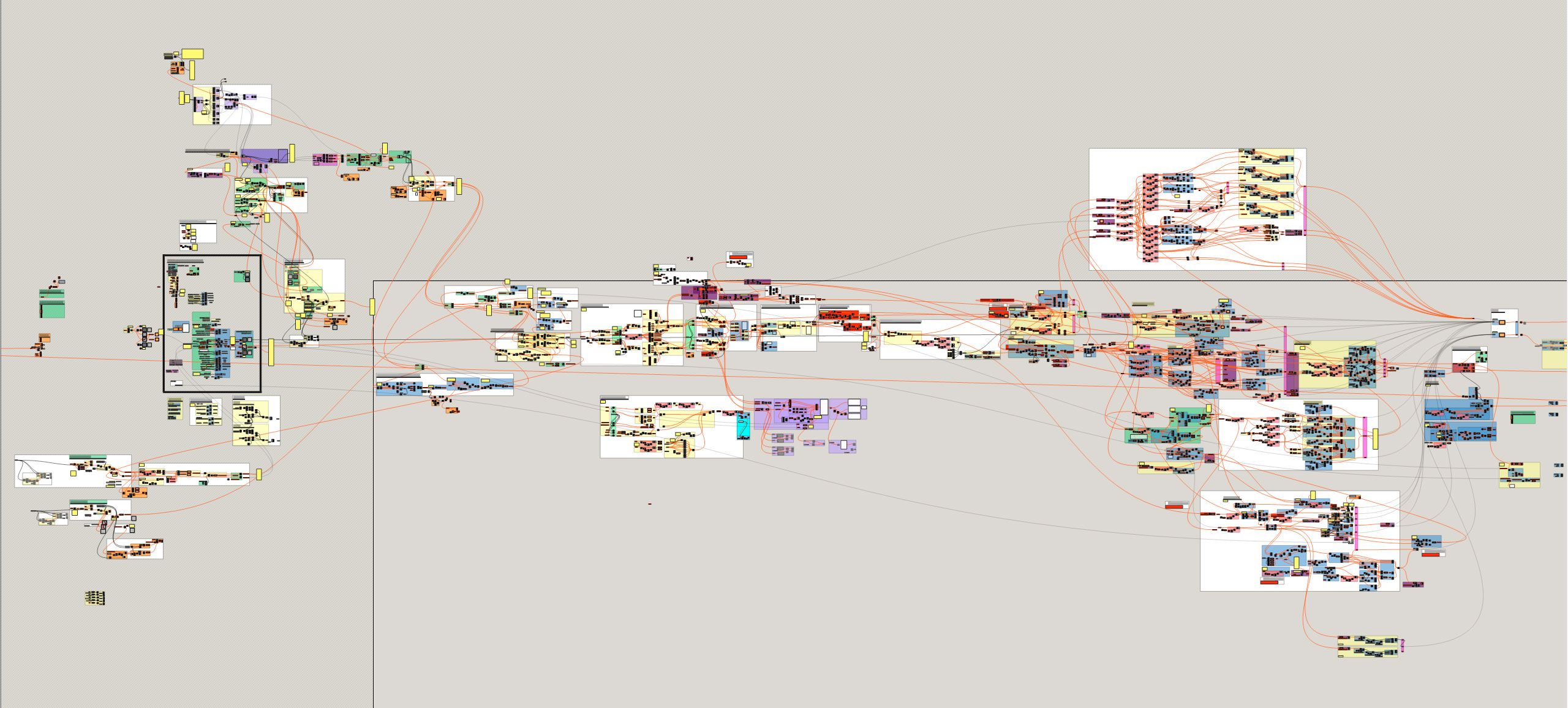
Figure 54: The final parametric model used to design Dermoid. While this model looks messy, the model’s creator has actually composed the model out of a hierarchy of modules that make it relatively easy to understand the model given its size and complexity. Many of these modules are reused from earlier iterations of the project.
After the November workshop the Danish team members took charge of finalising the parametric models as they prepared for Dermoid’s construction in March 2011 (fig. 51). This allowed me to observe how the structured models fared as major changes were made to them by designers unfamiliar with the model’s structure. Three critical modifications were made during this period:
- The models in stages B and C (fig. 52) were replaced by a model in Maya, which used Maya’s Nucleus engine to derive Dermoid’s overall form and pattern.
- The cambered beams were bifurcated into a wishbone structure.
- The beam details and construction documentation were refined for the specific construction materials and methods.
The first modification (using Maya to derive the form and pattern) was simply a case of swapping models. Since the Maya model returned all the expected outputs, the continuity of the project was preserved and none of the surrounding models had to change. The other two modifications (changing the topology of the beam and altering the construction documentation) required extensive adaptations to the existing parametric models. These changes were primarily carried out by a team member who joined the project during the November workshop. While they were initially unfamiliar with the models and my rationale for structuring the models, they required very little guidance in modifying them (they seldom contacted me for assistance). In order to make the changes, the designer chose to combine all the stages of the project together into one massive model (fig. 54). The resulting model contains 4086 nodes, which makes it twice as large as the largest model from chapter 4.3 and approximately two hundred times larger than the average Grasshopper model. Without prompting from me, the designer had carefully composed the model from a hierarchy of modules. Almost all of the modules from the original model had been reused, and these were complemented with a large number of new modules the designer had created. The reuse of the modules demonstrates that the designer could understand them well enough to apply them in a new context, despite being initially unfamiliar with the project. While the modules were cumbersome to create, this type of reuse demonstrates clear benefits to structuring a project in terms of improving understandability, collaboration, and reuse.
The complexities of Dermoid, both in terms of geometry and in terms of collaboration, place it on the limit of what is currently possible in parametric modelling – and perhaps beyond what is practical with an unstructured visual program. Breaking the project into a hierarchy of stages seemed to make it possible for designers to collaborate using disparate software, while the modules within the models seemed to promote model reuse and improve model understandability. At both scales, structure was difficult to impose at the start of the project and instead tended to emerge from an unstructured beginning to be later refactored with a few relatively minor changes. Perhaps most significantly, the flexibility of this working method facilitated the reorganisation of the design process, which enabled the designers to delay critical decisions until they had the best understanding of their consequences, rather than forcing the decisions early in order to avoid the cost of later changes.
6.6 – Sharing Modules Online
Figure 55: The homepage of parametricmodel.com as of 5 January 2013.
By structuring Dermoid’s parametric models I had amassed a library of modules able to be reused on other projects (as they were in later versions of Dermoid). In order to share these modules with other designers, I created the website parametricmodel.com, which lets anyone download and use the modules under the Creative Commons Attribution-ShareAlike licence (2007). The pages for each module intentionally resemble the documentation programmers provide with libraries of modules; the page for each module starts out with a short blurb, notes the modules inputs and outputs, and then enters into a detailed description of how the module works. At the time of writing, July 2012, parametricmodel.com has been running for twenty months, and in that time the 57 modules on the site have been downloaded 47,740 times by 19,387 people from 127 countries.13 While I do not have access to the projects the modules have been reused on, the 47,740 downloads indicate that the modules are reusable in a wide range of contexts and useful to a large number of designers.
Figure 56: T he hyperboloid module download page. Like documentation that comes with many programming languages, the download page details what the module does, the parameters it requires, and the outputs it produces.
With the success of the module downloads, I was also interested in whether parametricmodel.com could encourage designers to modularise their models and share them via the website. When I launched parametricmodel.com I designed the site so anyone could upload and share a module. In the module upload page I attempted to balance prescriptively enforcing a modular structure while minimising the obstacles to uploading. As such, the website coaxes users into creating modules by asking them to describe uploaded models with modular programming principles: defining the inputs and the outputs, describing the problem the module solves, and explaining how the module works. This has been relatively successful with all the uploaded models conforming to the modular pattern. Yet for all the modules downloaded, very few have been uploaded; for every thousand people who download a module, on average only one returns to contribute a new module. There are a whole host of reasons why architects may be reluctant to upload modules, which range from concerns about liability, to the effort and skill required in packaging a module, to a preference for contributing to other websites – particularly personal websites – where they may receive more control and more recognition. Despite the failure of parametricmodel.com to elicit a large number of contributions, it has been successful in demonstrating that thousands of designers want to reuse pre-packaged modules. As was shown with the Dermoid project, structure contributes to the reusability of components both by making them more understandable and by making them easier to extract for sharing. While structure may encourage sharing, there are other factors involved, including, intellectual property rights and the intrinsic rewards individuals receive for sharing. Parametricmodel.com shows how designers may benefit if these impediments are overcome, and the creation and sharing of modules becomes more widespread.
6.7 – Conclusion
Out at the edge of Copenhagen, out past the Royal Danish Academy of Fine Art, and in the secluded concrete studio filled with researchers from CITA and SIAL, we were facing a deceptively simple problem. The problem was not directly the one posed earlier – how can we fashion a doubly curved pavilion from a wooden reciprocal frame? With time the numerous difficulties of this proposition were solvable. Rather the deceptively simple problem was keeping the project flexible long enough for these discoveries to be made. Structuring Dermoid’s parametric models undoubtedly improved the project’s flexibility, enabling knowledge of Dermoid’s form and material strength to inform the project just days before construction.
I say the problem is deceptive because a model’s structure is not necessarily an obvious contributing factor to a project’s flexibility. Indeed, during the 1960s’ software crisis many software engineers overlooked the importance of program structure, often instinctively believing their woes were a product of perceived inadequacies in areas like project management. Today, however, structure is seen as so pivotally important to successful programming that even basic introductions to programming normally involve learning about structure, and some modern programming languages mandate the use of structure. Yet architects creating parametric models with visual programming languages are given only rudimentary tools for structuring projects and receive almost no guidance in the educational material on how to structure a project (one exception being Woodbury, Aish, and Kilian [2007] giving the structural recipes for common architecture problems). It is therefore not surprising that the majority of architects overlook something as deceptively simple as clearly naming parameters (81% do not name parameters) or using clusters in their Grasshopper models (97.5% do not use Grasshopper’s inbuilt modular structure, clusters; see chap. 6.3).
The widespread omission of structure in models created by architects makes for concerning statistics in light of the benefits structure provides. My thinking-aloud interviews seem to suggest that structure largely determines whether an architect can understand a model, which is a finding that confirms the existing research on the cognition of professional programmers. Yet using structure to cognitively jump “from a high level to a low level or vice versa” (Green and Petre 1996, 7) – such as professional programmers often do – proved to be difficult in the visual programming environments used by architects. From my experience structuring Dermoid’s parametric models, structure came from refactoring unstructured models rather than being the scaffold onto which programs are decomposed and composed as Meyer (1997, 40-46) suggests. Nevertheless, breaking Dermoid into a hierarchy of modules made it possible for designers to collaborate using disparate software, and offered them the continuity to make radical changes late in the project. The degree of flexibility within this structure challenged the orthodox progression of the design process, enabling details to be examined much earlier whilst allowing ordinarily pivotal decisions to be explored right up until the point of construction. In essence this was the antithesis of Paulson and MacLeamy’s front-loading (see chap. 2.2): rather than making decisions early in order to avoid the expense of changing them later, in Dermoid the cost of change was lowered to the point where critical decisions could be delayed until they were best understood. The structure also enabled parts of the models to be extracted and reused by designers initially unfamiliar with the models. While structure potentially encourages reuse, parametricmodel.com shows sharing requires more than an easily decomposed structure. These benefits of structure – in terms of reuse, understandability, continuity, and design process flexibility – remain largely unrealised by architects. While this is concerning, structure can be introduced with a few simple alterations. The most effective strategies seem to be clearly naming parameters, and grouping nodes together by function with defined inputs and outputs. I have posited in this chapter that architects do not realise the benefits of these simple structural changes due to both the limitations of design environments and the way architects are educated, an argument I will pick up again in the discussion.
Thesis Navigation
- Return to table of contents
- Goto previous chapter
- Goto next chapter
- Download entire thesis as PDF (30mb)
Footnotes
1:Center for Information Technology and Architecture at the Royal Danish Academy of Fine Arts, Copenhagen.
2:Spatial Information Architecture Laboratory at RMIT University, Melbourne.
3:At the meeting unstructured code was never singled out as one of the a causes of the software crisis. In fact, none of the attendees in the meeting minutes (Naur and Randell 1968) make reference to unstructured programming or the GOTO statement. They do however often talk about code structure and code modules. Dijkstra also presented a paper entitled Complexity Controlled by Hierarchical Ordering of Function and Variability where he describes grouping code into layers that are restricted so they can only communicate with layers above them. While there are structural principles to this idea, it is a different type of structure to the one Böhm and Jacopini (1966) discussed and that Dijkstra (1968) referred to in Go To Statement Considered Harmful. In essence, structure was an idea that was gaining traction around the time of the NATO conference, but one that was still in the early stages of taking shape.
4:While Böhm and Jacopini (1966) had shown that it was theoretically possible to write programs without the GOTO statement, this was not possible in practice until programming languages could accommodate Böhm and Jacopini’s three structures: sequence, iteration, and selection. Even after the development of these languages, programmers who were comfortable using the GOTO statement still used it. And nineteen years after Dijkstra’s (1968) original ACM letter – Go To Statement Considered Harmful – people were still writing rebuttals in the letters to the ACM like Frank Rubin’s (1987) “GOTO Considered Harmful” Considered Harmful.
5:Neither Python nor Ruby support the GOTO statement by default but it can be turned on in Ruby 1.9 by compiling with the flag SUPPORT_JOKE and it can be added to Python by importing a library Richie Hindle created as an April fools joke in 2004 (http://entrian.com/goto/). The jesting about adding GOTO to Ruby and Python speaks volumes of their relationship with the GOTO statement.
6:1553 of the sampled models were created in a version of Grasshopper that supported clusters (either below version 0.6.12 or above version 0.8.0) and of these models only 39 contained at least one cluster.
7:In the sample of 2002 Grasshopper models, 36% of the models contained at least one piece of text that explained what part of the model did; 30% of the models used one or more groups; 19% of the models had at least one node that named a branch of data; 2.5% of the models had clusters; and 48% had none of the above. This does not mean the other 52% are entirely structured; even though a model is structured by groups, and explanations, and names, their presence does not guarantee that the model is structured (for example, the unstructured models in figure 48 are part of the 52% since they both use groups). The percentage of unstructured models therefore falls somewhere between 48% and 97.5% depending on the definition of structure, but I would assume most definitions would conclude that at least 90% of the sampled models are unstructured.
8:A third explanation has been put forward by others I have spoken to: architects are under too much pressure to bother structuring their models. As Woodbury (2010, 9) puts it, architects quickly “find, skim, test and modify code for the task at hand” and then move onto the next one leaving “abstraction, generality and reuse mostly for ‘real programmers’.” I find this explanation unconvincing because it ignores the fact that many software engineers are also working under a lot of pressure. If software engineers and architects both experience pressure, then pressure alone does not explain why one group so studiously structures their programs while the other group almost never does.
9:At the time of writing (late 2012) Grasshopper is still under development. This description of clusters in Grasshopper helps explain why clusters and structure were not in the models I sampled, but it may not apply to models created in future versions of Grasshopper since the cluster implementation is likely to change.
10:This teaching method has been advanced since at least 1989 when Alexander Asanowicz argued at eCAADe “we should teach how to use personal computer programs and not programming.”
11:While I have chosen Beginning Python to illustrate this point, the same is true of almost any book on programming.
12:Design Patterns is in turn based upon the work of Christopher Alexander.
13:The ten most active countries being: United States, United Kingdom, Germany, Australia, Italy, Austria, Spain, France, Russia, and the Netherlands
Bibliography
Asanowicz, Alexander. 1989. “Four Easy Questions.” In Education Research and Practice: 8th eCAADe Conference Proceedings, edited by K. Agger and U. Lentz. Aarhus: School of Architecture Aarhus.
Bentley Systems. 2008. GenerativeComponents V8i Essentials. Exton, PA: Bentley Systems.
Burry, Mark. 2011. Scripting Cultures. Chichester: Wiley.
Böhm, Corrado, and Giuseppe Jacopini. 1966. “Flow Diagrams, Turing Machines And Languages With Only Two Formation Rules.” Communications of the Association for Computing Machinery 9 (5): 366-371.
Creative Commons. 2007. “Attribution-ShareAlike 3.0 Unported License Deed.” Accessed 19 November 2012. http://creativecommons.org/licenses/by-sa/3.0/.
Davis, Daniel, Jane Burry, and Mark Burry. 2011a. “Untangling Parametric Schemata: Enhancing Collaboration through Modular Programming.” In Designing Together: Proceedings of the 14th International Conference on Computer Aided Architectural Design Futures, edited by Pierre Leclercq, Ann Heylighen, and Geneviève Martin, 55-68. Liège: Les Éditions de l’Université de Liège. Selected as the best paper of CAAD Futures 2011.
Davis, Daniel, Jane Burry, and Mark Burry. 2011b. “Understanding Visual Scripts: Improving collaboration through modular programming.” International Journal of Architectural Computing 9 (4): 361-376.
Davis, Daniel, Flora Salim, and Burry Jane. 2011. “Designing Responsive Architecture: Mediating Analogue and Digital Modelling in Studio.” In Circuit Bending, Breaking and Mending: Proceedings of the 16th International Conference on Computer Aided Architectural Design Research in Asia, edited by Christiane Herr, Ning Gu, Stanislav Roudavski, and Marc Schnabel, 155–164. Newcastle, Australia: The University of Newcastle.
Dijkstra, Edsger. 1968. “Go To Statement Considered Harmful.” Communications of the Association for Computing Machinery 11 (3): 147–148.
Détienne, Françoise. 2001. Software Design: Cognitive Aspects. Translated and edited by Frank Bott. London: Springer.
Gamma, Erich, Richard Helm, Ralph Johnson, and John Vlissides. 1995. Design Patterns. Boston: Addison-Wesley.
Green, Thomas, and Marian Petre. 1996. “Usability Analysis of Visual Programming Environments: A ‘Cognitive Dimensions’ Framework.” Journal of Visual Languages & Computing 7 (2): 131-174.
Hilburn, Thomas, Iraj Hirmanpour, Soheil Khajenoori, Richard Turner, and Abir Qasem. 1999. A Software Engineering Body of Knowledge Version 1.0. Pittsburgh: Carnegie Mellon University.
Khabazi, Zubin. 2010. “Generative Algorithms using Grasshopper.” Morphogenesism. Accessed 19 November. http://www.morphogenesism.com/generative-algorithms.html.
Lewis, Clayton, and John Rieman. 1993. “Task-Centered User Interface Design: A Practical Introduction.” Accessed 19 November 2012. http://hcibib.org/tcuid/tcuid.pdf.
Loukissas, Yanni. 2009. “Keepers of the Geometry.” In Simulation and Its Discontents, edited by Sherry Turkle, 153–70. Massachusetts: MIT Press.
McCabe, Thomas. 1976. “A Complexity Measure.” IEEE Transactions on Software Engineering 2 (4): 308-320.
Meyer, Bertrand. 1997. Object-Oriented Software Construction. Second edition. Upper Saddle River: Prentice Hall.
Naur, Peter, and Brian Randell, eds. 1968. Software Engineering: Report on a Conference Sponsored by the NATO Science Committee. Garmisch: Scientific Affairs Division, NATO.
Nielsen, Jakob. 1993. Usability Engineering. San Diego: Morgan Kaufmann.
Nielsen, Jakob. 1994. “Guerrilla HCI: Using Discount Usability Engineering to Penetrate the Intimidation Barrier.” In Cost-justifying Usability, edited by Randolph Bias and Deborah Meyhew: 245-272. San Diego: Morgan Kaufmann.
Parnas, David. 1972. “On the Criteria To Be Used in Decomposing Systems into Modules.” Communications of the Association for Computing Machinery 15 (12): 1053-1058.
Payne, Andrew, and Rajaa Issa. 2009. “Grasshopper Primer.” Second edition. LIFT Architects. Accessed 19 November. http://www.liftarchitects.com/downloads/.
Payne, James. 2010. Beginning Python: Using Python 2.6 and Python 3.1. Indiana: Wiley.
Rittel, Horst, and Melvin Webber. 1973. “Dilemmas in a General Theory of Planning.” Policy Sciences 4(1973): 155–169.
Rubin, Frank. 1987. “‘GOTO Considered Harmful’ Considered Harmful.” Communications of the Association for Computing Machinery 30 (3): 195–196.
Side Effects Software. 2012. “Houdini User Guide.” Accessed Dec 20. http://www.sidefx.com/index.php?option=com_content&task=blogcategory&id=192&Itemid=346
Summit, Steve. 1996. C Programming FAQs: Frequently Asked Questions. Reading, MA: Addison-Wesley.
Wong, Yuk Kui, and John Sharp. 1992. “A Specification and Design Methodology Based on Data Flow Principles.” In Dataflow computing: Theory and Practice, edited by John Sharp, 37-79. Norwood: Ablex.
Woodbury, Robert, Robert Aish, and Axel Kilian. 2007. “Some Patterns for Parametric Modeling.” In Expanding Bodies: 27th Annual Conference of the Association for Computer Aided Design in Architecture, edited by Brian Lilley and Philip Beesley, 222–229. Halifax, Nova Scotia: Dalhousie University.
Woodbury, Robert. 2010. Elements of Parametric Design. Abingdon: Routledge.
Illustration Credits
- Figure 43 – Photograph by Daniel Davis, March 2011
- Figure 44 – Photograph by Anders Ingvartsen, March 2011
- Figure 45 – Photograph by Anders Ingvartsen, March 2011
- Figure 46 – Corrado Böhm and Giuseppe Jacopini 1966
- Figure 47 – Daniel Davis
- Figure 48 – Model-55 by Muhammad Nabeel Ahmed, http://www.grasshopper3d.com/forum/topics/apply-facade-on-surface; Model-1088 by Pieter Segeren, http://www.grasshopper3d.com/forum/topics/stepped-boxes-to-attractor.
- Figure 49 – Daniel Davis
- Figure 50 – Daniel Davis
- Figure 51 – Diagram by Daniel Davis with photographs by: Ansers Ingvartsen; Stephanie Braconnier; Anders Deleuran; and Pernille Klemp.
- Figure 52 – Daniel Davis
- Figure 53 – Daniel Davis
- Figure 54 – Dermoid design team
- Figure 55 – Screenshot of http://parametricmodel.com/, accessed January 2013
- Figure 56 – Screenshot of http://parametricmodel.com/Hyperboloid/35.html, accessed January 2013