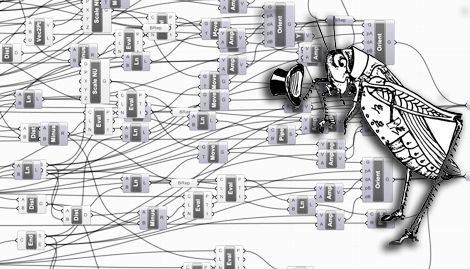
This semester I have been teaching two papers at RMIT that have involved getting students up to speed with Grasshopper. There are already some excellent tutorials on how Grasshopper works – my favorite is Zubin M Khabazi's Generative Grasshopper Tutorials – Lift Architects and Woo Jae also have some helpful advice. However, there seems to be little advice on avoiding a big balls of tangled Grasshopper spaghetti. So I am going to share some of my thoughts on how using design patterns can help avoid tangling yourself in Grasshopper bézier curves.
Why spaghetti is bad
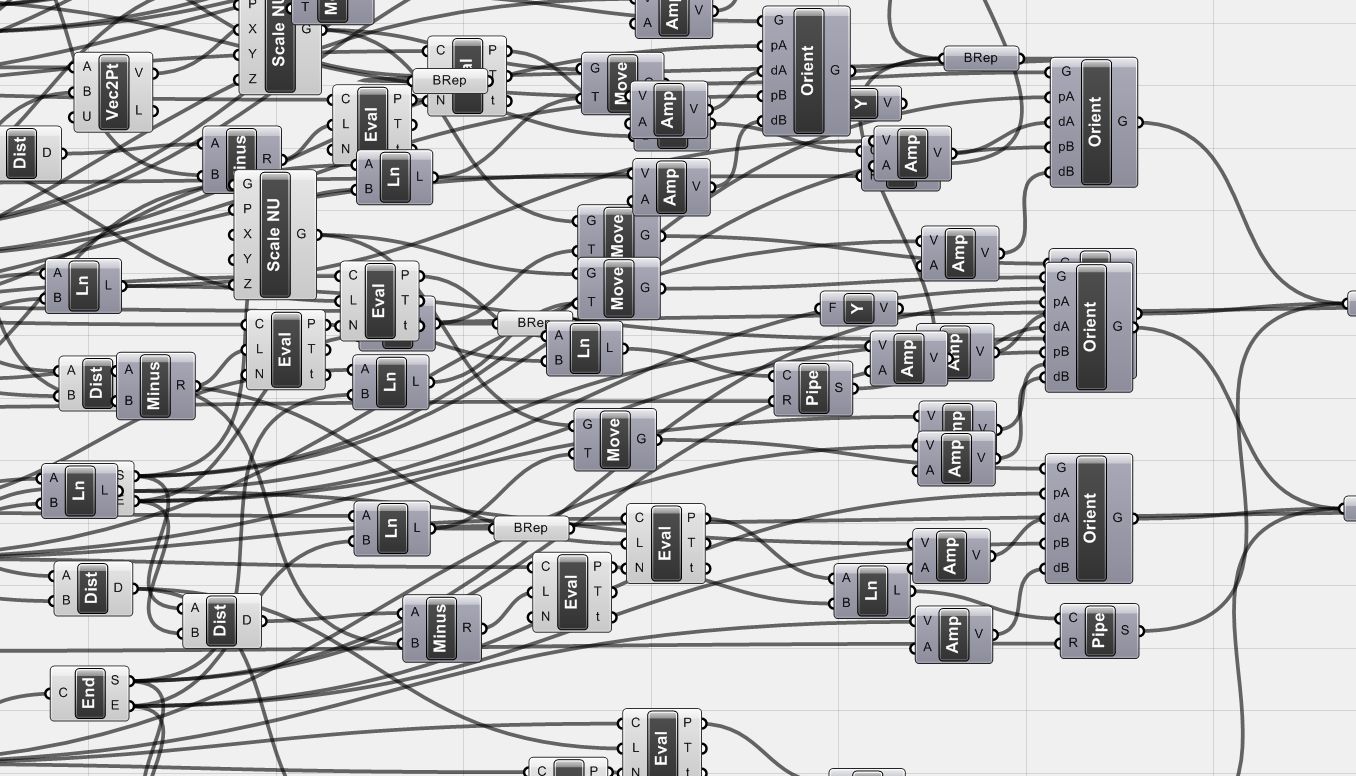
Unfortunately not a joke
Spaghetti is the technical name for a tangled mess of code, sometimes called The Big Ball of Mud. Often when you are producing spaghetti everything will be fine, but when it comes to editing or reusing spaghetti things can be pretty painful. Spaghetti can make it almost impossible to understand what your code does because understanding it involves following the paths of all the wildly connected data-streams. It makes editing the code difficult because you do not know what removing a node does or how to reconnect the other nodes when you do. It can also make it hard to trace problems through the code. And you will never be able to merge two balls of spaghetti together. Gah.
Functions in Grasshopper
One of the most basic strategies for avoiding Spaghetti is to break your problem down into small tasks. This is pretty much how all programming languages manage code and this was even a feature in Grasshopper until it got mysteriously dropped (I am still hoping they dropped it because they are working on something better). You want to break the problem into distinct units of work, which can be described in a short sentence. For example, in the Copenhagen project, we were distributing wooden elements onto an elliptical surface. This can be broken down into four main tasks: generating the elliptical surface, placing points on the surface, placing the wooden elements on the points, and analysing the wooden elements.
Once you have your problem broken down, you should consider what data you need to perform each task and what data each task will return. So for generating an elliptical surface, the inputs to the task are: the center of the surface and the scale of the surface in the x, y, z space. The output of the task is a surface. I like to create a column of parameters for the inputs and a column for the outputs. This both helps explain what data your task is using and it makes it easy to reuse the function in the future.
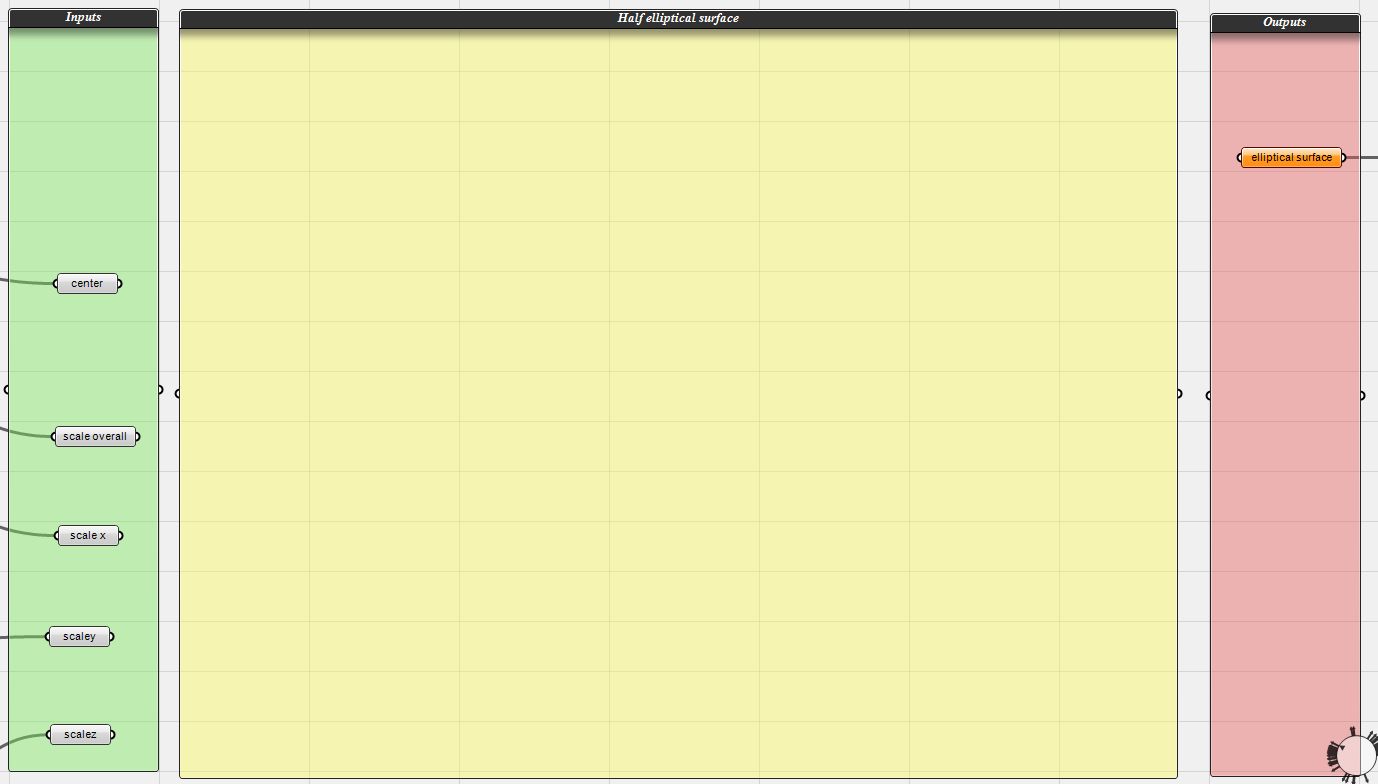
Inputs and outputs all setup
Once all that is in place all that is left to do is fill in the steps to transform the inputs into the outputs.
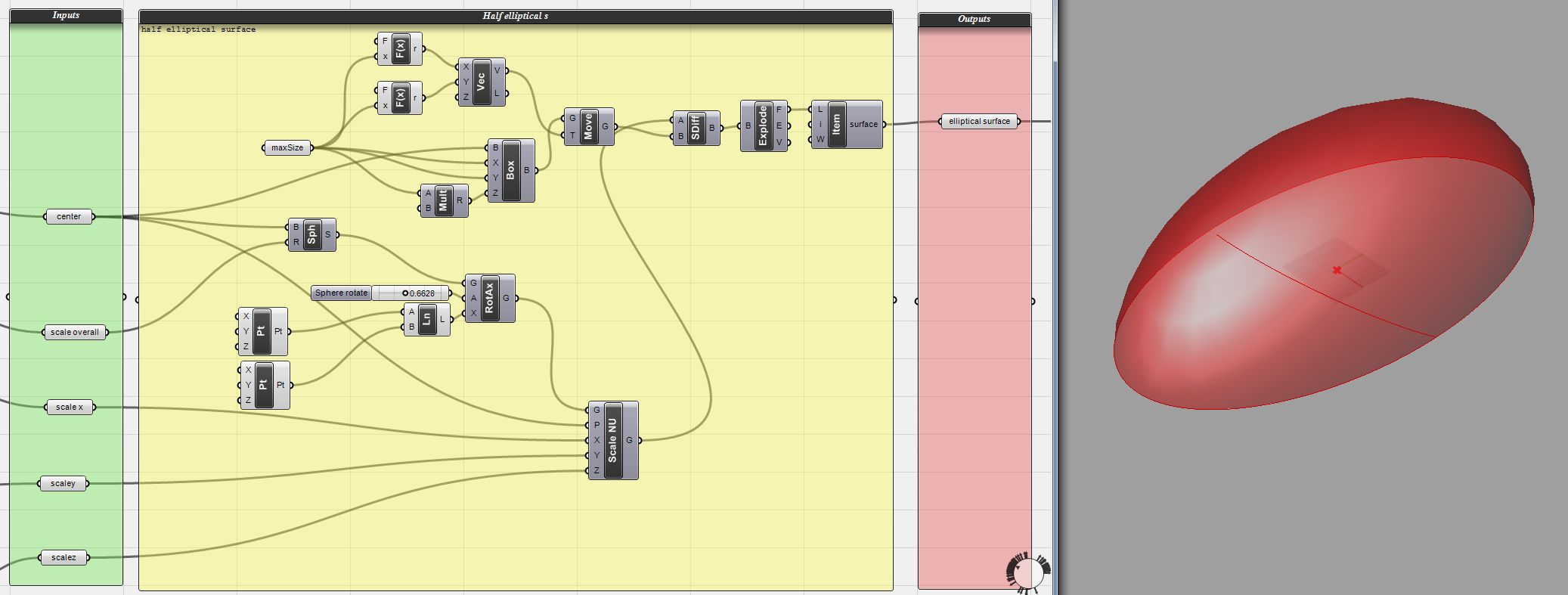
Final function
There are some really big advantages to this method:
- Your definition becomes easier to understand. Rather than trying to follow big long tangled links, you can see the main steps of the program. Then within each task, even if you do not fully understand what is going on inside the task, you can clearly see what data the task requires and what data it returns.
- You can test a project in parts. Because every task is independent of the other tasks, you can easily put data into the inputs and verify the output of the task is correct. If something goes wrong with your model you can check each task is functioning, rather than trying to test the whole project at once.
- It is easier to reuse your work. When you copy a task to a new location, because the inputs and outputs are explicitly defined and clearly labeled, all you need to do is reconnect these inputs and outputs to the right data sources. Similarly, it is easy to swap tasks in and out of the model when the inputs and outputs are defined. So if we decided we no longer wanted to use an elliptical surface because the elliptical surface has an explicit output node, we could just connect a free form surface to that node. No more trying to follow a curves through the definition to link them back up when something changes.
Design patterns in Grasshopper
Once you start designing with functions for a while, you will start to see common patterns occurring. In computer science, the patterns that form code are called design patterns. In a strange instance of progress folding back in on itself, design patterns are an idea that was originally taken by computer scientists from Christopher Alexander, and now we are borrowing these ideas back to help code architecture. Robert Woodbury, Robert Aish, and Axel Kilian developed a set of design patterns for parametric architecture, displayed in this excellent website. The patterns are for Generative Components but are applicable to Grasshopper. I personally find myself frequently using The Jig, The Controller, and The Place Holder.
shervin ansari
i like your programs
(grasshopper)
Andre Philippi
Hi Daniel,
I'm a former Software Engineer learning Grasshopper after a long career break. I just found your website, have been reading some of your articles and agree with you in many things, including bringing Best Practices from the Software industry to Architecture and Design industries.
One quick question regarding the Design Patterns article: In Grasshopper, how do you generate the input/output column of parameters that you display on your article, please? I noticed that your input/output columns have input/output wiring connectors. I have been looking into GH Clusters and groups but could not find anything similar to what you show on your article.
Thank you in advance, and keep up with the great work :)
Andre
Daniel
Hey Andre,
I manually created the input/output columns. Basically I just put a colored text box behind the parameters (if you use the number, point, or string parameter, you can pass data through it without manipulating the data). You should also checkout Meta hopper, which I think can do this automatically: http://www.food4rhino.com/app/metahopper
Daniel