Recently I have been producing parametric models for Antoni Gaudí's Sagrada Família; in Excel. When I agreed to use Excel to produce the models, I signed on certain I would fail, such was the unlikeliness of Excel succeeding in producing parametric architecture. While I cannot say much about the project, I should say that we were only using Excel for research purposes and that the design of the Sagrada Família remains one of the worlds most technologically advanced architectural projects. Using Excel drove me pretty close to the wall, particularly at 2am on a Friday as I got the model ready for a deadline and was trying to figure out a formula for a circle intersecting a plane in three dimensions. After two weeks on Excel I am not a convert, but I have begun to re-evaluate the worth of the more technologically advanced tools.
One of the curiosities of Excel is that cell relationships are hidden. A cell displays data and the only way to see relationships is to click on the data and view the formula. This is the inverse of graph based parametric modelling tools like Grasshopper and GC, which graphically represent the relationship between nodes but hide the data - in Grasshopper you need to hover over each node to see the enclosed data. Both approaches achieve a similar result, which got me thinking about why architects use the graph based approach while Excel still uses the spreadsheet based approach.
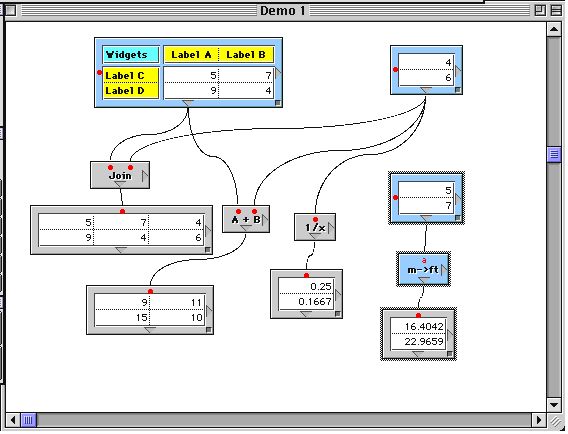
I am not the first person to consider this. In 1997, Spreadsheet 2000 competed against Excel with a graph based spreadsheet (shown above), which looks suspiciously similar to Grasshopper, complete with Bezier curves. Incredibly Spreadsheet 2000 was itself created with a graph based programming tool, Prograph, by Steve Wilson who went on to become the vice president of systems at Oracle, where he still probably maps out systems using graphs. This must have all seemed pretty advanced in 1997, it still looks advanced today, yet Spreadsheet 2000 failed before reaching the year 2000.
There does not seem to be any analysis on why Spreadsheet 2000 failed [update 27 June 2014: Steve Wilson commented below and explained the real reason, everything beyond here is inaccurate speculation], so I am going to speculate: relationships don't matter. The problem Spreadsheet 2000 was trying to solve was the invisibility of relationships in spreadsheets (Wilson talks about the aims of Spreadsheet 2000 here). The solution was to use a directed graph that exposed the relationships between cells. The graph is successful in doing this, although its verbosity makes it inefficient compared to a normal spreadsheet. For example the relationship between the top right table and the bottom middle table is inversion. Using a graph this takes up a significant amount of interface real-estate - two lines and an intermediate node depicting 1/x - it could have just as easily been communicated by adding a column to the top right data headed 'Inverse'. The inefficiency of the graph increases with complexity since more nodes make it more difficult to interpret individual relationships from the spaghetti of code.
By exposing the relationships, Spreadsheet 2000 aimed to reduce errors. This is not the case. There is no correlation between knowing the relationships between cells and the number of errors. Stephen Powell's "A Critical Review of the Literature on Spreadsheet Errors," references a study where one group of participants were given a spreadsheet on paper so they could not see the cell relationships, another group were given an electronic copy so they could see the formula, and both groups identified a similar number of errors in the spreadsheet, 50%.* Anecdotally I agree with this; I have never stared at the Grasshopper graph and gone 'there is my mistake,' I do however see errors in the 3d model and then find myself working back through the graph, hovering over each node to see what the data inside looks like.
Spreadsheet 2000's failure seems to be a common occurrence for visual programming paradigms. It is only in parametric architecture that I have really seen graph based tools like Grasshopper and GC become so widely adopted. I am unsure of why this is the case. After using Excel I feel there is still room to improve on these paradigms, particularly the emphasis they place on relationships, which are often only needed at the time of construction. Despite this, unless you are Gaudí, I wont be giving up my graph based representations again.
Download Spreadsheet 2000 here
* Similar research has been done by the European Spreadsheet Risks Interest Group, a group that gives me considerable comfort knowing that someone is looking out for our accountants and the risks they face.
Sivam
very interesting discussion. Excel is excellent for generative design. Genoform one of the first parametric design software works mainly on XL.
Only designers, think visually. engineers and accountants don't. Wonder if that will help explain why spread sheet 2000 failed ?
As generative design matures most equations will be handled by the CAD program as in solid works. Rhino is inherently not parametric hence its parametric engine needs to have its workings exposed, if it was excel designers would not have embraced it the way they have embraced grasshopper. So it was a right decision on their part. Whether it is the way of the future is yet to be seen.
Just started an open generative design initiative based on XL in www.opengenerativedesign.com which may be of interrest.
David Murphy
Your web site (generative design) throws an error
Forbidden You don't have permission to access / on this server.
Additionally, a 404 Not Found error was encountered while trying to use an ErrorDocument to handle the request.
Sivam
We were under spam attach. So the site is down. Sorry about that.
Sivam
logon
if it was excel designers would not have embraced it the way they have embraced grasshopper. So it was a right decision on their part. Whether it is the way of the future is yet to be seen.
Daniel
I agree that Grasshopper's popularity with designers is tied to its visual interface. It remains to be seen if Grasshopper is anything more than a sketch engine. I think the visual interface will have some difficulty translating people from their initial playing into a serious design. Then again perhaps it does not need to; with products like Digital Project on the market, perhaps Grasshopper only needs to operate in the design stages.
Sivam krish
This is a very interesting discussion I think there are two issues here :
1) People like the final output to be what they are familiar with (charts for excel and 3D designs for rhino). So they revisit change to final output.
2) The key different in grasshopper and spread sheet, in that in spread sheet development its only data that is often changed. The structure is often stable; where as in grasshopper the structure is under evolution.
So there are scenarios one is for designing the structure and the other is for changing data within stable structures. I think if people are trying to use figure out the best combination of formulas to create a spread sheet output - they would probably for the visual scripting route , but that is not what spread sheets are used for.
Steve Wilson
I just stumbled into this blog, so I'm commenting a little late, but it's fun to see the discussion! I wrote Spreadsheet 2000 with my own two hands -- and then licensed it to Casady & Greene to market it. The eventual failure of the product was really related to two things:
1. I choose to write it in a niche programming language that was never ported to work on Windows. That left us limited to a Mac-only market at the exact time Apple was closest to dying (and Mac marketshare was down near 1%)
2. A some point in the development of the software, I noticed the World Wide Web had been invented! In fact, the small company up the hall from me sold their little web page editor to Adobe for millions of dollars! The opportunities there were huge, and I was working on a technology that I could not figure out how to apply to the web.
Given the impact of #1 and #2 I would up packing in the company going on to become an early member of the Java development team at Sun Microsystems. Market forces really had more to do with the demise of Spreadsheet 2001 than the core metaphor. Many people honestly loved and used it heavily.
As you say, making the relationships explicit (rather than hidden) creates its own set of complexity (while removing other problems). The basic row/column/formula metaphor of a spreadsheet has issues, but many of them get handled by increasingly clever features being packed into packages like Excel. Way back in 97, we had a long-list of simplifying features we were planning to add to Spreadsheet 2000, but we just never got to get to them. It would have been interesting to see where it all went!
Daniel
Hi Steve, thank you for getting in touch and giving the real story behind Spreadsheet 2000! I've included a note in the text to direct people to your comment rather than my dodgy speculation.
It's amazing to look back at Spreadsheet 2000. It's a remarkable product that still looks modern all these years later. You might like to know that many architects today use software similar to spreadsheet 2000 to design their buildings: http://en.wikipedia.org/wiki/Grasshopper_3d I like to think in some way, even if you couldn't continue spreadsheet 2000, that the ideas you were exploring probably influenced other software developers, who influenced others, who built the tools architects use. So I guess it lives on in a way. And the question you were trying to answer, of explicit vs implicit relationships, is still being debated, still unsolved.
Steve Wilson
Daniel, it was through stumbling onto your article that I found Grasshopper and spent much of yesterday looking into it. Honestly, I was flabbergasted (in a good way!). It looks like such an excellent product. I feel like in some parallel universe my little company could have kept developing software and produced something like that. It has so many of the kinds of things we only dreamt about including almost 20 years ago when we were first creating Spreadsheet 2000. Thanks for your excellent post and for helping me find Grasshopper. It gave me a glimpse into what might have been! :-)